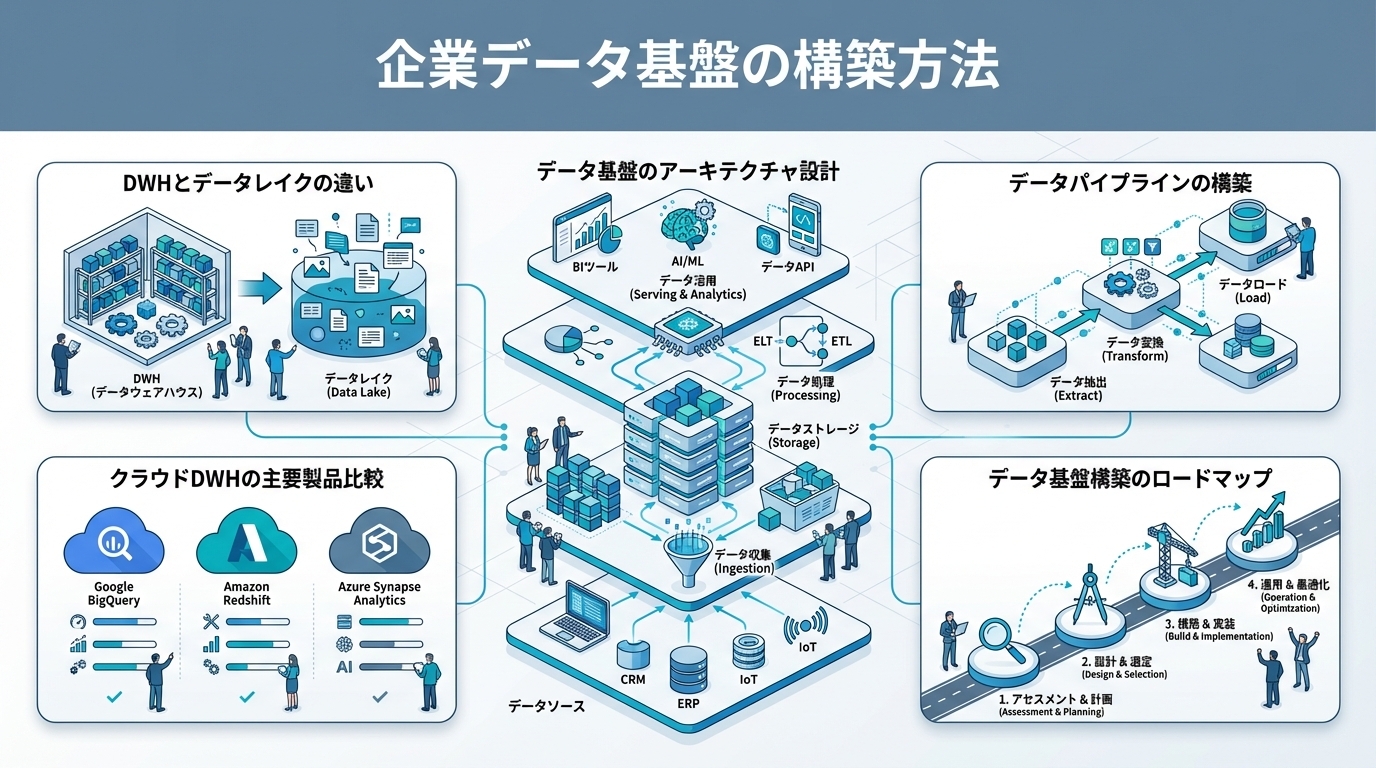
データ基盤とは、企業内の様々なデータソースからデータを収集・統合・蓄積し、分析・活用できる状態にする技術基盤です。構造化データの分析にはDWH(データウェアハウス)、非構造化データを含む大量データの蓄積にはデータレイクを使い分けます。クラウドDWHはBigQuery・Snowflake・Amazon Redshiftが主要製品で、中小企業はBigQueryのサーバーレス型が最も着手しやすいです。
DXの推進に伴い、CRM、ERP、MA、Webアナリティクスなど多数のシステムにデータが分散する企業が増えています。各システムのデータを統合的に分析するには、全社データを集約する「データ基盤」の構築が不可欠です。
データ基盤とは、企業内の様々なデータソースからデータを収集・統合・蓄積し、分析・活用できる状態にするための技術基盤です。本記事では、DWH(データウェアハウス)とデータレイクの違い、クラウドDWHの選定、データパイプラインの構築方法を解説します。
本記事は「データドリブン経営の進め方|データに基づく意思決定を組織に実装するステップ」シリーズの一部です。
DXのツール選定について体系的に学びたい方は、DXツール・インフラガイドで全体像を把握できます。
この記事でわかること
- DWH(構造化データ分析向け)とデータレイク(大量非構造化データ蓄積向け)の違いと使い分け — 近年は両者の境界が曖昧になり、「レイクハウス」と呼ばれるDWHとデータレイクを統合したアーキテクチャが主流になりつつあります(Databricks。
- BigQuery・Snowflake・Amazon Redshiftの機能・価格・適性の比較 — 多くの中小企業にはBigQueryが最も適しています。
- ELT/ETLパイプライン、データマート、セマンティックレイヤーなどアーキテクチャ設計の基本 — クラウドDWHの計算能力を活用するELTが現在の主流です。
- CRMデータを含むデータパイプラインの構築手順と運用のポイント — 1.HubSpotAPI→Fivetran(ETLツール)→BigQuery。
企業データ基盤の構築方法について理解を深めたい方に、特に参考になる内容です。
DWHとデータレイクの違い
| 比較項目 |
DWH |
データレイク |
| データの種類 |
構造化データ |
構造化+半構造化+非構造化 |
| スキーマ |
事前定義(Schema on Write) |
利用時定義(Schema on Read) |
| 用途 |
定型的な分析・レポーティング |
探索的分析、機械学習 |
| データ品質 |
クレンジング済みの高品質データ |
生データを含む |
| ユーザー |
経営層、ビジネスアナリスト |
データサイエンティスト、エンジニア |
| コスト |
中〜高 |
低〜中 |
近年は両者の境界が曖昧になり、「レイクハウス」と呼ばれるDWHとデータレイクを統合したアーキテクチャが主流になりつつあります(Databricks、Delta Lake等)。
関連するテーマとして、API連携とシステム統合の設計もあわせてご覧ください。
クラウドDWHの主要製品比較
| 製品 |
提供元 |
特徴 |
価格モデル |
適する企業 |
| BigQuery |
Google Cloud |
サーバーレス、SQL対応、高速 |
従量課金(クエリ量) |
全規模 |
| Snowflake |
Snowflake |
マルチクラウド、コンピュートとストレージ分離 |
従量課金(使用量) |
中堅〜大企業 |
| Amazon Redshift |
AWS |
AWS統合、高パフォーマンス |
固定+従量 |
AWS環境の企業 |
| Azure Synapse |
Microsoft |
Microsoft統合、PaaS |
従量課金 |
Microsoft環境の企業 |
中小企業への推奨
多くの中小企業にはBigQueryが最も適しています。理由は:
- サーバーレスで運用管理が不要
- 月10GBまでのストレージと1TBまでのクエリが無料
- Looker Studioとの統合でBIダッシュボードが構築しやすい
- SQLで操作できるため、学習コストが低い
関連するテーマとして、データクレンジングの方法もあわせてご覧ください。
データ基盤のアーキテクチャ設計
3層アーキテクチャ
| 層 |
役割 |
構成要素 |
| データソース層 |
データの発生源 |
CRM、ERP、Webサイト、SaaS各種 |
| データ統合層 |
収集・変換・格納 |
ETL/ELTパイプライン、DWH |
| データ活用層 |
分析・可視化・活用 |
BIツール、機械学習、レポート |
ETLとELTの違い
| 方式 |
処理順序 |
特徴 |
適する場面 |
| ETL |
Extract→Transform→Load |
変換してからDWHに格納 |
データ品質を重視 |
| ELT |
Extract→Load→Transform |
まずDWHに格納し、DWH上で変換 |
BigQuery等のクラウドDWH向け |
クラウドDWHの計算能力を活用するELTが現在の主流です。dbt(data build tool)はELTのTransform部分を効率化するツールとして広く使われています。なお、データパイプラインの構築と並行してAIによるデータ分析の自動化を導入すれば、蓄積したデータからのインサイト抽出も効率化できます。
関連するテーマとして、データドリブン経営の進め方もあわせてご覧ください。
データパイプラインの構築
CRMデータの統合例
CRM(HubSpot等)のデータをBigQueryに集約し、BIダッシュボードで可視化する構成です(関連記事: CRM × データウェアハウス連携の設計)。
構成:
- HubSpot API → Fivetran(ETLツール)→ BigQuery
- freee API → Fivetran → BigQuery
- BigQuery上でdbtを使ってデータモデリング
- Looker Studio/Tableauでダッシュボード作成
主要なETL/ELTツール
| ツール |
特徴 |
価格 |
| Fivetran |
マネージドETL、300+コネクタ |
従量課金 |
| Airbyte |
オープンソース、自前運用可 |
無料〜 |
| trocco |
日本製、国内SaaS対応 |
月額5万円〜 |
| Stitch |
シンプル、Talend傘下 |
従量課金 |
データ基盤構築のロードマップ
| フェーズ |
期間 |
内容 |
| Phase 1 |
0〜3ヶ月 |
CRMのダッシュボード活用(DWH不要) |
| Phase 2 |
3〜6ヶ月 |
CRM + 会計データのDWH統合 |
| Phase 3 |
6〜12ヶ月 |
全社データの統合、高度な分析 |
| Phase 4 |
12ヶ月〜 |
AI/ML活用、予測分析 |
中小企業はPhase 1から始めて十分です。DX戦略の策定方法と組み合わせてロードマップを描くと効果的です。CRMの標準ダッシュボード機能でかなりのデータ分析が可能です(関連記事: CRM導入の進め方完全ガイド)。データ量やユースケースが増えた段階でDWHを導入するのが、コスト効率の良いアプローチです。
HubSpotで実現する企業データ基盤の構築方法
企業データ基盤の構築方法を実務に落とし込むには、CRMツールの活用が不可欠です。詳しくは「HubSpot Data Hubとは?データ同期・自動化・レポート機能を徹底解説」で解説しています。
次のステップ
企業データ基盤に取り組むなら、CRM・データ基盤の整備が成功の鍵です。以下の記事でHubSpotを使った具体的な実践方法を解説しています。
HubSpot ゴールドパートナーが開発・提供
HubSpotと会計ソフトの連携には、HubSpotゴールドパートナーのStartLinkが開発する連携アプリが利用できます。freee会計とはSync for freee、マネーフォワード クラウドとはSync for Money Forwardで、取引情報からの見積書・請求書作成や取引先・品目の同期が可能です。主要なクラウド会計ソフトの双方に対応しているため、経理体制に合わせて選択できます。
あわせて読みたい
まとめ
- データ基盤はDWH(構造化データ分析)とデータレイク(非構造化データ蓄積)を使い分ける
- クラウドDWHの主要製品はBigQuery(サーバーレス・手軽)、Snowflake(柔軟・マルチクラウド)、Redshift(AWS統合)
- 中小企業はBigQueryでのスモールスタートが最も現実的。従量課金で初期コストが低い
- CRMのデータをDWHに連携し、営業・マーケ・CS・経理のデータを統合分析する体制を構築する
- データパイプラインは「収集→変換→蓄積→提供」の4層で設計し、品質チェックを各層に組み込む
DX推進の全体像についてはDX完全ガイドで基礎から実践まで体系的に解説しています。
よくある質問(FAQ)
Q1. データ基盤としてDWHとデータレイクはどちらを選ぶべきですか?
用途によります。DWH(データウェアハウス)は構造化データの集計・分析に最適で、売上レポートやKPIダッシュボードに適しています。データレイクは構造化・非構造化を問わず全データを格納でき、AI/ML用の分析基盤に適しています。中小企業はまずDWH(BigQuery、Snowflake等)から始め、必要に応じてデータレイクを追加する段階的アプローチが推奨されます。
Q2. データサイロとは何ですか?どう解消しますか?
データサイロとは、部門ごとに異なるシステムやExcelにデータが分散し、相互に参照・連携できない状態です。解消するには、CRMを全社データの統合基盤として位置づけ、各システムとAPI連携でデータを集約する方法が効果的です。iPaaSを活用すればノーコードでの連携も可能です。
Q3. クラウドDWHのコストはどの程度ですか?
BigQueryは従量課金制で、月額数千円から利用できます。Snowflakeも利用量に応じた課金です。中小企業の一般的な利用量であれば月額1〜5万円程度で運用可能です。オンプレミスのDWHと比較すると、初期投資が不要でスケーラビリティが高い点がメリットです。
StartLinkのHubSpot 基盤による データ活用サポート
StartLinkはHubSpotゴールドパートナーとして、CRM・SFA・MAの設計・導入・運用を一気通貫で支援しています。顧客データ・営業データ・マーケティングデータをHubSpotに集約し、現場と経営層が同じ数字を見られるCRM基盤づくりをご提案します。加えて、独自開発した Sync for freee により HubSpot と freee 会計をリアルタイム連携。さらに Claude Code エージェントを活用したAI業務自動化で、レポート作成や定型業務の省力化もご提案可能です。
なお、DWH・データレイクの構築代行、大規模データ基盤の設計実装、基幹システムのリプレースは対応範囲外です。HubSpot を起点にした顧客データ × 会計データ × AIの領域に特化してご支援します。
まずはHubSpotで顧客データを一元化するところから始めたい方は、お気軽にご相談ください。