この記事の結論
TypeScript SDKまたはPython SDKを使えば、社内APIや独自業務フローに特化したMCPサーバーを自作できます。ツール定義・リソース公開・PromptTemplate設計の実装手順から、Claude Codeへの接続・デバッグ方法まで、実践ガイドとして解説します。
TypeScript SDKまたはPython SDKを使えば、社内APIや独自業務フローに特化したMCPサーバーを自作できます。ツール定義・リソース公開・PromptTemplate設計の実装手順から、Claude Codeへの接続・デバッグ方法まで、実践ガイドとして解説します。
HubSpotゴールドパートナーのStartLinkが、HubSpot導入・AI活用・CRM整備・業務効率化までをまとめて支援しています。記事で気になったテーマを、そのまま相談ベースで整理できます。
TypeScript SDKまたはPython SDKを使えば、社内APIや独自業務フローに特化したMCPサーバーを自作できます。ツール定義・リソース公開・PromptTemplate設計の実装手順から、Claude Codeへの接続・デバッグ方法まで、実践ガイドとして解説します。
——「既存のMCPサーバーでは自社の業務フローに合わない」「社内APIをAIエージェントから直接叩けるようにしたい」。MCPの導入が進む中で、こうしたニーズに直面する開発チームが急速に増えています。
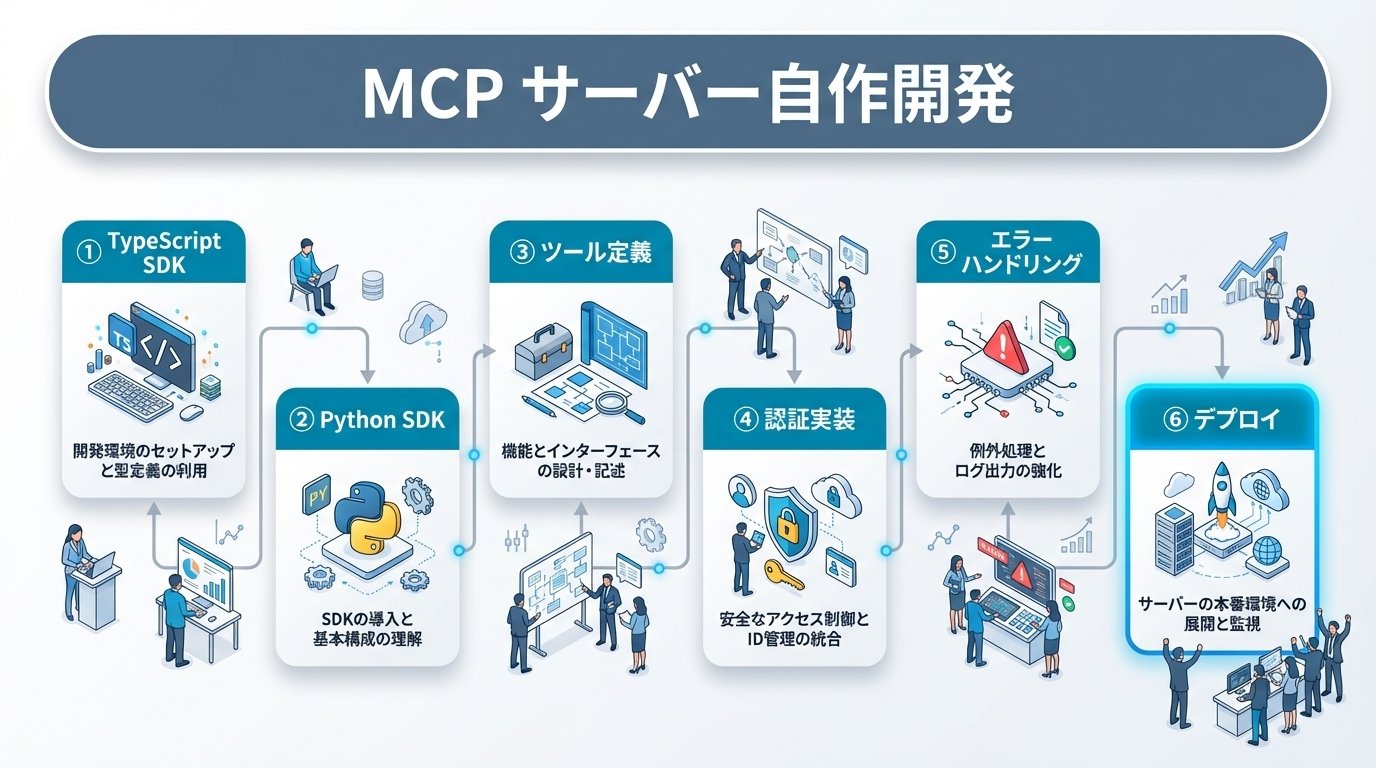
Anthropic社が公開したModel Context Protocol(MCP)は、AIモデルと外部システムをつなぐオープンスタンダードとして広がりを見せていますが、公開されているMCPサーバーは汎用的なものが中心です。自社独自の業務ロジックや社内APIをMCP対応させるには、MCPサーバーを自作する必要があります。AI活用完全ガイドで、AI活用の全体像を把握できます。
CRM特化型コンサルタントとして、HubSpot MCPサーバーやfreee MCPサーバーを日常的に活用している立場から言えば、MCPサーバーの自作は「AIエージェントの可能性を自社業務に最適化するための最短ルート」です。本記事では、TypeScript SDKとPython SDKの選定基準から、ツール定義の設計パターン、認証・エラーハンドリングの実装まで、独自MCPサーバーを開発するために必要な知識を体系的に解説します。
自社独自のMCPサーバーを開発し、業務ツールとAIエージェントを接続したいエンジニアに向けた記事です。
2026年3月時点で、MCPのエコシステムには数千のサーバーが公開されています。HubSpot、Slack、Notion、GitHub、Google Workspaceなど主要SaaSのMCPサーバーは充実していますが、以下のケースでは自作が必要になります。
| ケース | 具体例 | 自作が必要な理由 |
|---|---|---|
| 社内専用API | 在庫管理システム、独自CRM、社内ナレッジDB | 公開サーバーが存在しない |
| 業務ロジックの組み込み | 見積計算、与信判断、承認フロー | 汎用サーバーでは業務ロジックを表現できない |
| 複数システムの統合操作 | CRM + 会計 + 在庫の横断クエリ | 個別サーバーの組み合わせでは非効率 |
| セキュリティ要件 | オンプレミス限定、特定IPレンジ制限 | 公開サーバーではセキュリティポリシーに合わない |
| パフォーマンス最適化 | 大量データの事前集約、キャッシュ戦略 | 汎用サーバーでは応答速度が不十分 |
ここが結構ミソなのですが、MCPサーバーの自作は「既存のAPIラッパーを書く」こととは根本的に異なります。MCPサーバーは、AIモデルが「どのツールを使うべきか」を自律的に判断するためのメタ情報(ツールの説明文、入力スキーマ、アノテーション)を含む設計が求められます。単にAPIを呼べるだけでは不十分で、AIが適切に判断できるよう、ツールの意味・用途・副作用を正確に記述する必要があるのです。
自作するかどうかの判断は、以下の3つの軸で整理すると明確になります。
MCPサーバーの自作に入る前に、プロトコルの基本構造を把握しておくことが重要です。MCPサーバーは、AIモデル(クライアント)からのリクエストを受け取り、外部データソースやツールへの橋渡しを行うミドルウェアです。プロトコルはJSON-RPC 2.0をベースとしており、以下の3つのプリミティブで構成されています。
| コンポーネント | 役割 | 具体例 |
|---|---|---|
| ツール(Tools) | AIが実行できるアクション | データベース検索、API呼び出し、ファイル操作 |
| リソース(Resources) | AIが参照できるデータ | ドキュメント、設定ファイル、データベースレコード |
| プロンプト(Prompts) | 事前定義されたテンプレート | レポート生成テンプレート、分析クエリテンプレート |
MCPの通信は、クライアント(Claude、ChatGPT、Cursorなど)がサーバーに対してinitializeリクエストを送信するところから始まります。サーバーはサポートする機能(capabilities)を返し、クライアントはtools/listで利用可能なツールを取得します。この動的ディスカバリーの仕組みにより、事前のハードコーディングなしにAIが利用可能な機能を把握できます。
MCPサーバーのトランスポートには、ローカルプロセス間通信のstdioと、ネットワーク経由のStreamable HTTPの2種類があります。
stdioトランスポート: MCPサーバーをローカルプロセスとして起動し、標準入出力でやり取りします。個人の開発環境やチーム内での利用に最適で、デプロイの手間がかかりません。
Streamable HTTPトランスポート: 2025年3月のプロトコル更新で、従来のSSE(Server-Sent Events)に代わり標準となりました。単一のHTTPエンドポイントでPOSTとGETの両方を処理でき、既存のHTTPインフラ(ロードバランサー、CDN、WAF)との親和性が高いことが特徴です。社外のユーザーや複数チームに公開する場合に適しています。
MCPの公式SDKは、TypeScriptとPythonの2つが提供されています。どちらもMCPプロトコルの全機能をサポートしていますが、特性が異なります。
| 比較軸 | TypeScript SDK | Python SDK |
|---|---|---|
| GitHubリポジトリ | modelcontextprotocol/typescript-sdk | modelcontextprotocol/python-sdk |
| スキーマ定義 | Zod | Pydantic |
| トランスポート | stdio / Streamable HTTP | stdio / Streamable HTTP |
| 型安全性 | TypeScriptの型システムで静的チェック | 型ヒント + Pydanticで実行時バリデーション |
| 非同期処理 | Node.js のイベントループ | asyncio |
| デプロイ先 | Vercel / Cloudflare Workers / AWS Lambda | AWS Lambda / Google Cloud Functions / 自社サーバー |
| 推奨ユースケース | Webアプリ連携、フロントエンドとの統合 | データ分析、ML連携、既存Pythonシステムとの統合 |
| コミュニティ規模 | MCPサーバーの多くがTS製(参考実装が豊富) | データサイエンス系の連携事例が多い |
TypeScript SDK: 既存のNode.js/TypeScriptプロジェクトへの組み込み、Webアプリ(Next.js等)との統合、リファレンス実装の参照(多くがTS製)に適しています。
Python SDK: 既存のPythonシステム(Django、FastAPI)へのMCP追加、データ分析・ML連携、Pydanticベースのバリデーション活用に適しています。
ここでは、TypeScript SDKを使って社内の顧客情報APIをMCP対応させるサーバーを実装します。以下が最小構成のコードです。
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { z } from "zod";
// MCPサーバーのインスタンスを作成
const server = new McpServer({
name: "internal-crm-server",
version: "1.0.0",
description: "社内CRMの顧客情報をAIエージェントから検索・更新するためのMCPサーバー",
});
// ツール定義: 顧客を検索する
server.tool(
"search_customers",
"顧客名・メールアドレス・会社名で顧客情報を検索します。部分一致で検索され、最大20件を返します。",
{
query: z.string().describe("検索キーワード(顧客名、メールアドレス、会社名のいずれか)"),
limit: z.number().optional().default(10).describe("取得件数の上限(デフォルト: 10、最大: 20)"),
},
async ({ query, limit }) => {
// 社内APIを呼び出す
const response = await fetch(`https://internal-api.example.com/customers/search`, {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${process.env.INTERNAL_API_TOKEN}`,
},
body: JSON.stringify({ query, limit: Math.min(limit, 20) }),
});
if (!response.ok) {
return {
content: [{ type: "text", text: `検索に失敗しました: ${response.statusText}` }],
isError: true,
};
}
const customers = await response.json();
return {
content: [{
type: "text",
text: JSON.stringify(customers, null, 2),
}],
};
}
);
// サーバーを起動
const transport = new StdioServerTransport();
await server.connect(transport);このコードが示すように、MCPサーバーの基本構造は非常にシンプルです。McpServerのインスタンスを作成し、server.tool()でツールを定義し、StdioServerTransportで接続するだけです。
ツール定義において最も重要なのは、description(説明文)の品質です。AIモデルはこの説明文を読んで「どのツールを使うべきか」を判断します。
以下の原則を守ることで、AIの判断精度が大きく向上します。
z.string().describe("検索キーワード(顧客名、メールアドレス、会社名のいずれか)")2025年11月のプロトコル更新で追加されたツールアノテーション機能により、ツールが「読み取り専用(readOnly)」か「データ変更あり(destructive)」かをメタデータとして宣言できるようになりました。これにより、クライアント側でユーザー確認のフローを自動的に挿入するなど、安全性の高いエージェント体験を構築できます。ツールの説明文だけでなく、構造化されたアノテーションで副作用を明示することが、本番運用では重要です。
ツール数が増えてきたら、src/配下にサーバー本体、ツール定義、リソースハンドラーを分離する構成を推奨します。ツールごとにファイルを分割することで、チーム開発時の競合を防ぎ、テストの粒度を細かくできます。.well-known/mcp.jsonにサーバーのメタデータを配置すれば、クライアントが自動的にサーバーを発見できるServer Discoveryにも対応できます。
Python SDKでは、FastMCPクラスを使うことで、デコレータベースの直感的なツール定義が可能です。
from mcp.server.fastmcp import FastMCP
from pydantic import BaseModel, Field
import httpx
mcp = FastMCP(
"internal-crm-server",
description="社内CRMの顧客情報をAIエージェントから検索・更新するためのMCPサーバー"
)
class CustomerSearchResult(BaseModel):
id: str
name: str
email: str
company: str
status: str
@mcp.tool()
async def search_customers(
query: str = Field(description="検索キーワード(顧客名、メールアドレス、会社名)"),
limit: int = Field(default=10, le=20, description="取得件数の上限")
) -> list[CustomerSearchResult]:
"""顧客名・メールアドレス・会社名で顧客情報を検索します。部分一致で最大20件を返します。"""
async with httpx.AsyncClient() as client:
response = await client.post(
"https://internal-api.example.com/customers/search",
json={"query": query, "limit": limit},
headers={"Authorization": f"Bearer {os.environ['INTERNAL_API_TOKEN']}"},
)
response.raise_for_status()
return [CustomerSearchResult(**c) for c in response.json()]
if __name__ == "__main__":
mcp.run()Python SDKのFastMCPは、関数のdocstringをツールの説明文として、型ヒントとPydanticのFieldをスキーマ定義として自動的に利用します。TypeScript SDKに比べてコード量が少なく、Pythonに慣れた開発者にとっては取り回しが楽です。
MCPサーバーの認証設計では、3つのレイヤーを区別して考える必要があります。
| レイヤー | 説明 | 実装例 |
|---|---|---|
| クライアント認証 | MCPクライアント(Claude Desktop等)がMCPサーバーに接続する際の認証 | OAuth 2.1、APIキー |
| バックエンド認証 | MCPサーバーが社内APIや外部サービスに接続する際の認証 | 環境変数でのトークン管理 |
| ユーザー認証 | エンドユーザーの権限に基づくアクセス制御 | JWTトークン、RBAC |
stdioトランスポートの場合: クライアント認証はトランスポート層で不要です(ローカルプロセスとして起動されるため)。バックエンド認証のみ実装すれば十分です。環境変数で社内APIのトークンを管理するのが一般的なパターンです。
Streamable HTTPトランスポートの場合: リモートサーバーとして公開するため、クライアント認証が必須になります。MCPの仕様ではOAuth 2.1が推奨されています。
stdioトランスポートでの典型的な設定例を示します。Claude Desktopの設定ファイル(claude_desktop_config.json)で環境変数を渡す形です。
{
"mcpServers": {
"internal-crm": {
"command": "node",
"args": ["./dist/server.js"],
"env": {
"INTERNAL_API_TOKEN": "your-api-token-here",
"DATABASE_URL": "postgresql://user:pass@localhost:5432/crm"
}
}
}
}認証情報はコードにハードコードせず、必ず環境変数で管理します。MCPのセキュリティ設計の詳細はMCPのセキュリティリスクと実践的な対策ガイドを参照してください。
MCPサーバーのエラーハンドリングは、AIエージェントが「エラーの原因を理解して次のアクションを判断できる」ことを目標に設計します。単にエラーを投げるのではなく、AIが読み取れる形でエラー情報を返すことが重要です。
// エラーハンドリングのパターン(抜粋)
if (response.status === 404) {
return {
content: [{ type: "text", text: `顧客ID "${customerId}" は存在しません。search_customersツールで検索できます。` }],
isError: true,
};
}
if (response.status === 429) {
return {
content: [{ type: "text", text: "APIレート制限に達しました。30秒後に再試行してください。" }],
isError: true,
};
}ポイントは、エラーメッセージの中に次のアクションのヒントを含めることです。「顧客IDが存在しません」だけでなく、「search_customersツールで検索できます」と書くことで、AIエージェントが自律的にリカバリー操作を選択できるようになります。
既存の社内APIをMCPサーバーとして公開する手順を整理します。
Step 1: API仕様の棚卸し
まず、社内APIのエンドポイント一覧を整理し、MCPツールとして公開する範囲を決定します。すべてのAPIエンドポイントをMCPツール化する必要はありません。AIエージェントが使う可能性のある操作だけに絞ります。
Step 2: ツール粒度の設計
ここが結構ミソなのですが、MCPのツール粒度はREST APIのエンドポイント粒度とは異なります。REST APIではGET /customersとGET /customers/:idは別のエンドポイントですが、MCPツールとしては「顧客検索」と「顧客詳細取得」を1つのツールにまとめるか、分けるかを「AIの判断しやすさ」の観点で設計します。
Step 3: 入力スキーマの定義
Zod(TypeScript)またはPydantic(Python)でスキーマを定義します。AIモデルが正しい値を渡せるよう、各フィールドのdescriptionを充実させることが成功の鍵です。
Step 4: エラーハンドリングの実装
前節で解説したパターンに従い、AIが理解できるエラーメッセージを設計します。
Step 5: テストとデバッグ
MCPサーバーのテストには、MCP Inspectorが便利です。ブラウザベースのUIからツールを直接呼び出してレスポンスを確認できます。
npx @modelcontextprotocol/inspector node ./dist/server.jsHubSpot ゴールドパートナーが開発・提供
議事録や社内ナレッジをNotionで管理しているなら、HubSpotゴールドパートナーのStartLinkが提供する連携アプリ「Sync for Notion」の活用が有効です。HubSpotのCRM画面からNotionページやデータベースを直接操作でき、ワークフローによる自動連携やプロパティのマッピングにも対応します。詳細はSync for Notionで確認できます。
HubSpot CRMでは標準オブジェクト(コンタクト、取引、会社)に加えて、カスタムオブジェクトを作成できます。例えば「プロジェクト管理」や「サブスクリプション管理」のカスタムオブジェクトを作成している企業は多いでしょう。
公式のHubSpot MCPサーバーは標準オブジェクトの操作に対応していますが、業務固有のカスタムオブジェクトを操作するには、専用のMCPサーバーを自作するか、既存サーバーを拡張する必要があります。
自作MCPサーバーを使えば、「この取引に紐づくプロジェクトの進捗を教えて」「サブスクリプションの更新期限が今月中の顧客を一覧にして」といった業務固有の問い合わせに、AIエージェントが直接応答できるようになります。
HubSpot MCPサーバーの基本的な活用方法についてはHubSpot MCPサーバーによるCRM操作の自動化で詳しく解説しています。
MCPサーバーの開発を効率化するツール群を紹介します。
| ツール | 用途 | 公式/サードパーティ |
|---|---|---|
| MCP Inspector | ブラウザUIでツール呼び出しをテスト | 公式 |
| Claude Desktop | 実際のAIクライアントでの動作確認 | Anthropic |
| Claude Code | CLIベースでの高速テスト・反復開発 | Anthropic |
MCP CLI (mcp dev) |
Python SDK付属の開発サーバー | 公式 |
Claude Code Hooksを活用した開発自動化と組み合わせることで、MCPサーバーのコード変更時に自動でテストを実行する仕組みも構築できます。なお、Claude Codeを活用した経営データの可視化やコンテンツマーケティングの支援についても、具体的な取り組みをご紹介しています。
stdioトランスポートの場合、console.logの出力はMCPの通信を妨害します。ログ出力にはconsole.error(stderr)を使うか、server.sendLoggingMessage()を使用してください。
// NG: stdioを汚染する
console.log("Processing request...");
// OK: stderrに出力する
console.error("[DEBUG] Processing request...");
// OK: MCP標準のログメッセージ
server.sendLoggingMessage({
level: "info",
data: "Processing customer search request",
});ツール(Tools)がMCPサーバーの中心的な機能ですが、リソース(Resources)とプロンプト(Prompts)を組み合わせることで、AIエージェントの活用幅が大きく広がります。
リソースはURI形式で識別し、AIが参照できるデータを公開します。静的リソース(設定ファイル、ドキュメント)はサーバー起動時に登録し、動的リソース(データベースレコード、APIレスポンス)はリソーステンプレートを使って定義します。例えば、社内のナレッジベースをリソースとして公開すれば、AIエージェントが回答時に参照できるようになります。
プロンプトテンプレートは、特定のワークフローに最適化された入力パターンを事前定義する機能です。たとえば「月次売上レポートの生成」というプロンプトテンプレートを定義しておけば、AIは必要なパラメータ(対象月、部門)を自動的にユーザーに確認し、適切なツールを順番に呼び出します。
MCPサーバーのデプロイ先は、コンテナ(Docker/Kubernetes)、サーバーレス(AWS Lambda、Google Cloud Functions)、従来のVMなど、Streamable HTTPに対応していれば自由に選択できます。Cloudflareは自社のWorkers環境でMCPサーバーのホスティングを公式サポートしており、エッジ環境での低レイテンシ運用が可能です。
stdioトランスポートであれば、ローカルプロセスとして起動するだけでデプロイ不要です。チーム内での利用であればstdioで十分ですが、社外公開や複数チームへの展開を見据えるなら、早い段階でStreamable HTTP + コンテナの構成を検討するのが現実的です。
本番環境では、MCPサーバーのヘルスチェックエンドポイントを設置し、接続先データソースの可用性を定期的に確認します。ツール呼び出しのレイテンシ、エラー率、同時接続数をメトリクスとして収集し、異常時にアラートを発報する体制を整えましょう。
MCPの通信はJSON-RPCベースのため、リクエストとレスポンスのペイロードを構造化ログとして記録できます。ただし、ログにユーザーの機密データが含まれる可能性があるため、PII(個人識別情報)のマスキング処理を実装することが重要です。
MCPサーバーの自作にあたって、正直に把握しておくべき制限事項があります。
プロトコルの進化途上: MCPは2025年末にStreamable HTTPトランスポートが追加されるなど、仕様が進化し続けています。SDKのバージョンアップに伴い、コードの修正が必要になる可能性があります。
LLMの判断精度への依存: ツールの説明文やスキーマの品質がAIの判断精度に直結します。「動くけれどAIが正しく使ってくれない」という問題は、コードの品質ではなくメタ情報の品質に起因することがほとんどです。
セキュリティの自己責任: 自作サーバーのセキュリティは開発者が担保する必要があります。特にStreamable HTTPで公開する場合、認証・認可・レート制限・入力バリデーションを自前で実装する必要があります。
デバッグの難しさ: AIエージェントが「なぜそのツールを選んだか」「なぜそのパラメータを渡したか」のデバッグは、従来のAPIデバッグとは質が異なります。ツールの説明文を微調整しながら反復テストするプロセスが必要です。
HubSpot ゴールドパートナーが開発・提供
会計ソフトとHubSpotを別々に運用していると、見積・請求データの二重入力が発生しがちです。HubSpotゴールドパートナーのStartLinkが提供する連携アプリを使えば、freee会計はSync for freee、マネーフォワード クラウドはSync for Money Forwardで、取引情報からの請求書・見積書作成や取引先・品目の同期を自動化できます。freee・マネーフォワード両対応で主要クラウド会計をカバーします。
ツール1〜3個の小規模なサーバーであれば、1〜2日で開発からテストまで完了できます。10個以上のツールを持つ本格的なサーバーの場合、設計・実装・テスト・ドキュメント整備を含めて1〜2週間が目安です。SDKが提供するボイラープレートが充実しているため、プロトコルの理解さえあれば実装作業自体はスムーズに進みます。
2026年3月時点では、TypeScript SDKの方が参考実装やコミュニティの事例が豊富です。Anthropic公式のリファレンスサーバーもTypeScriptで書かれているものが多く、初めてMCPサーバーを自作する場合はTypeScript SDKから始めるのが効率的です。ただし、Python SDKも急速にエコシステムが拡大しており、特にデータ分析やML連携の領域ではPython SDKの事例が充実しています。
個人の開発環境やチーム内での利用であれば、stdioトランスポートが最もシンプルです。サーバーをnodeやpythonのプロセスとして起動するだけで使えるため、デプロイの手間がかかりません。一方、社外のユーザーや複数チームに公開する場合、Streamable HTTPトランスポートが適しています。ただし、OAuth 2.1認証やHTTPSの設定が追加で必要になります。
MCP Inspector(npx @modelcontextprotocol/inspector)を使うのが最も効率的です。ブラウザベースのUIからツールを直接呼び出し、レスポンスの形式や内容を確認できます。また、ユニットテストとしてMCPクライアントライブラリを使ってサーバーにプログラマティックに接続し、各ツールの入出力を検証する方法も推奨されています。
Claude Desktopの設定ファイル(macOSの場合~/Library/Application Support/Claude/claude_desktop_config.json)のmcpServersセクションに、サーバーの起動コマンドと環境変数を記述します。設定後にClaude Desktopを再起動すると、ツールバーにMCPサーバーのアイコンが表示され、登録したツールが利用可能になります。
HubSpot APIのカスタムオブジェクトエンドポイントをラップするMCPツールを自作します。標準MCPサーバーではカスタムオブジェクトの操作に制限があるため、業務で本格的に活用するなら自作が現実的です。
TypeScriptまたはPythonの基本的な開発経験と、REST APIの基本概念の理解があれば十分です。MCPプロトコル自体は公式ドキュメント(modelcontextprotocol.io)を一読すれば概要を把握できます。
株式会社StartLinkは、事業推進に関わる「販売促進」「DXによる業務効率化(ERP/CRM/SFA/MAの導入)」などのご相談を受け付けております。 サービスのプランについてのご相談/お見積もり依頼や、ノウハウのお問い合わせについては、無料のお問い合わせページより、お気軽にご連絡くださいませ。
