この記事の結論
企業のナレッジ管理が破綻する構造的な原因とSlackの立ち位置。Slackの会話ログからFAQを自動生成するAI活用手法。
企業のナレッジ管理が破綻する構造的な原因とSlackの立ち位置。Slackの会話ログからFAQを自動生成するAI活用手法。
HubSpotゴールドパートナーのStartLinkが、HubSpot導入・AI活用・CRM整備・業務効率化までをまとめて支援しています。記事で気になったテーマを、そのまま相談ベースで整理できます。
企業のナレッジ管理が破綻する構造的な原因とSlackの立ち位置。Slackの会話ログからFAQを自動生成するAI活用手法。
——「それ、前にSlackで誰かが答えてたんだけど…」。この一言を、あなたのチームでは何回聞いたことがあるでしょうか。Slackには膨大な業務知識が蓄積されていますが、そのほとんどは整理されないまま流れ去り、検索しても見つけられず、同じ質問が繰り返されています。AI活用完全ガイドで、AI活用の全体像を把握できます。
この「宝の持ち腐れ」状態を変えるのがAIです。Slackの会話ログをAIで分析し、暗黙知を形式知に変換する。FAQを自動生成し、プロジェクトの知見をアーカイブし、新入社員のオンボーディングを加速する。本記事では、その具体的な方法論と実践手法を体系的に解説します。詳しくは「生成AIとは?ビジネス活用の全体像をわかりやすく解説」で解説しています。
関連する記事の一覧は生成AI実務活用ガイドをご覧ください。
企業のナレッジには3つの層があります。
| 層 | 内容 | 保存状態 |
|---|---|---|
| 公式ドキュメント | マニュアル、仕様書、FAQ | Wiki/Notionで管理されている |
| 半公式ナレッジ | 議事録、レビューコメント、設計メモ | ツール内に散在 |
| 暗黙知 | ベテランの判断基準、トラブル対応ノウハウ | Slackの会話に埋もれている |
3番目の「暗黙知」が最も価値が高く、かつ最も失われやすい情報です。ベテラン社員がSlackで後輩に教えたトラブルシューティングの手順、顧客対応で得た教訓、「この場合はこうする」という判断基準——これらはSlackのメッセージとして流れ去り、検索しなければ二度と出会えません。
Slackの検索機能は基本的にキーワードマッチです。しかし、暗黙知は「こういう問題が起きたときにどうしたか」という文脈的な情報であり、正確なキーワードがわからなければ検索できません。
ここが結構ミソなのですが、ナレッジ管理の問題は「情報がない」のではなく「情報にたどり着けない」ことです。AIによるセマンティック検索や要約が、このギャップを埋めます。こうした取り組みの詳細は、経営データの可視化やコンテンツマーケティングの支援のページでもご紹介しています。
HubSpot ゴールドパートナーが開発・提供
議事録や社内ナレッジをNotionで管理しているなら、HubSpotゴールドパートナーのStartLinkが提供する連携アプリ「Sync for Notion」の活用が有効です。HubSpotのCRM画面からNotionページやデータベースを直接操作でき、ワークフローによる自動連携やプロパティのマッピングにも対応します。詳細はSync for Notionで確認できます。
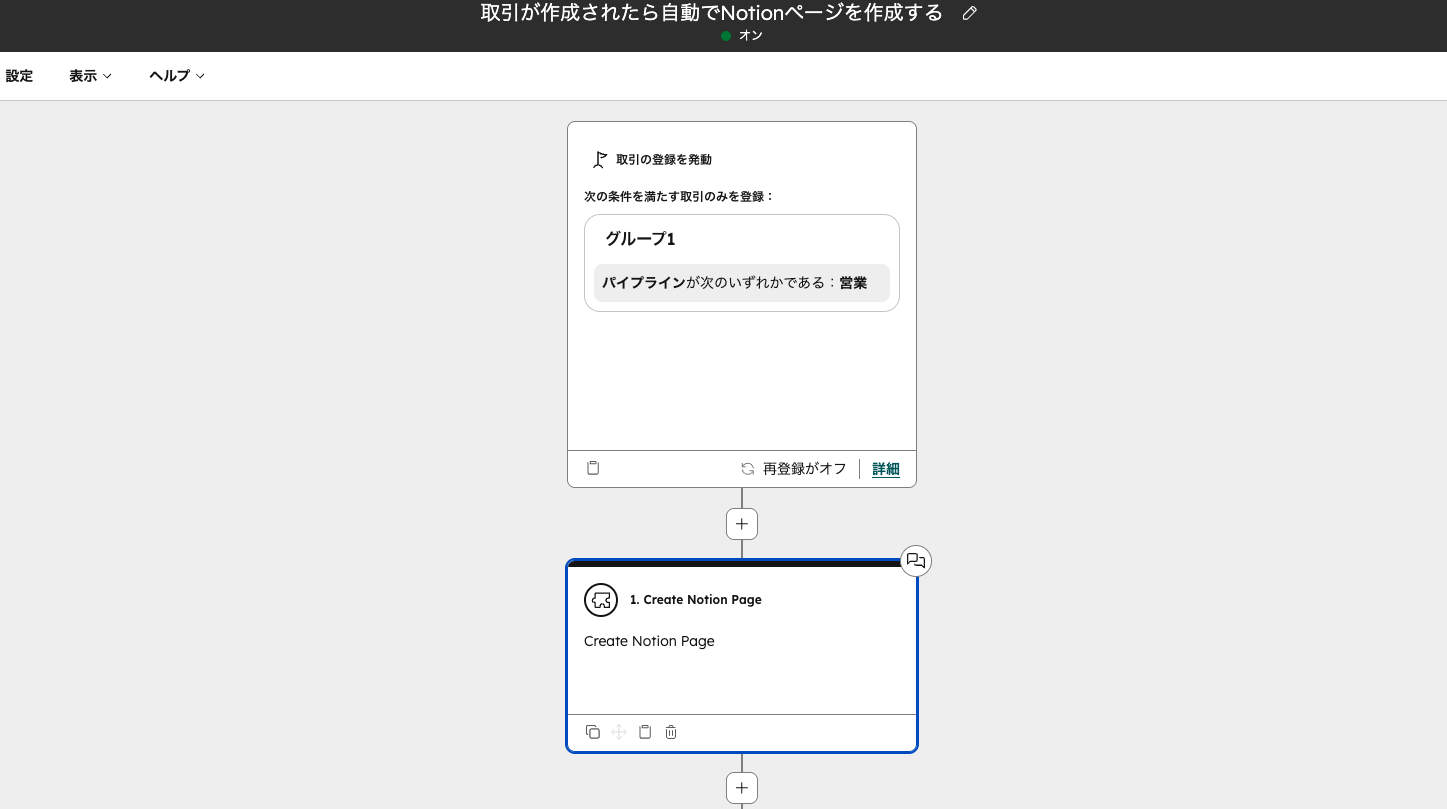
引用:Sync for Notion|ワークフローアクションでNotionページを自動作成
Slackに毎日流れ込む会話の大半は暗黙知であり、そのままでは翌日には誰も参照しない情報として消えていきます。AIを活用してこの流動データを構造化すれば、同じFAQが生成され、過去プロジェクトの意思決定ログがアーカイブされ、新人オンボーディング資料が半自動で整備されるようになります。「流れて消えるデータ」を「検索・再利用可能な資産」に変換することこそが、組織ナレッジマネジメントの本質です。HubSpotなどのCRMと連携させれば、顧客対応ナレッジを営業チーム全体で共有する基盤にもなり、属人的なノウハウが組織の競争優位に変わります。最初の一歩としては、同じ質問が何度も繰り返されている1つのSlackチャンネルを選び、AIでFAQを自動生成してみてください。数日運用するだけで「このチャンネルは何を繰り返し聞かれているのか」が可視化され、ナレッジ化すべき領域が自然と浮かび上がります。
Slack会話ログ
│
▼
[データ抽出・前処理]
├── Q&A形式の会話を抽出
├── 質問の分類・クラスタリング
└── 重複質問の統合
│
▼
[AI処理(LLM)]
├── 質問の一般化(固有名詞→汎用表現)
├── 回答の要約・構造化
└── カテゴリ自動分類
│
▼
[FAQドキュメント生成]
├── Notion / Confluence に自動投稿
└── Slack Canvasに反映Slackの全メッセージからQ&Aを抽出するには、以下のパターンを検知するルールを設計します。
| パターン | 検知ルール | 例 |
|---|---|---|
| 明示的な質問 | 「?」で終わるメッセージ | 「この機能の設定方法は?」 |
| 暗黙的な質問 | 「〜について教えてください」「〜がわかりません」 | 「権限設定の方法がわかりません」 |
| 回答が付いたスレッド | 質問メッセージに3件以上のスレッド返信 | (自動判定) |
| リアクション付き回答 | :white_check_mark: や :+1: が3つ以上 | チームが「有用」と認めた回答 |
AIが生成したFAQの品質を担保するために、以下の仕組みを組み込みます。
| 仕組み | 説明 |
|---|---|
| 自動レビュー通知 | 生成されたFAQを元のスレッド投稿者にDMで確認依頼 |
| 鮮度管理 | FAQ作成日から90日経過したら「要更新」フラグを付与 |
| 利用追跡 | FAQが参照された回数を記録し、人気順にソート |
| フィードバックループ | 「この回答は役に立ちましたか?」のリアクション投票 |
プロジェクトが終了すると、そのSlackチャンネルは非アクティブになり、やがてアーカイブされます。しかし、プロジェクトで得た知見——どんな課題があり、どう解決し、何を学んだか——はチャンネルの会話に散在したままです。
| フェーズ | 処理 | 頻度 |
|---|---|---|
| 日次サマリー | その日のチャンネル会話をAIで要約 | 毎日(営業日終了後) |
| 週次レポート | 週単位の進捗・課題・決定事項をAIが整理 | 毎週金曜 |
| マイルストーン記録 | 重要な意思決定・方針変更を検知して記録 | イベントドリブン |
| プロジェクト終了時 | 全期間の知見をAIが「振り返りレポート」として生成 | プロジェクト終了時 |
AIが生成する振り返りレポートのフォーマット例:
## プロジェクト振り返りレポート(自動生成)
### 基本情報
- プロジェクト名: ○○
- 期間: YYYY/MM/DD 〜 YYYY/MM/DD
- 参加メンバー: ○名
### 主要な成果
1. ○○を実装し、△△の効率が□%改善
2. ...
### 直面した課題と解決策
| 課題 | 解決策 | 学び |
|------|--------|------|
| APIレートリミットに頻繁に到達 | バッチ処理に変更 | 初期設計段階でスループットを見積もるべき |
| ... | ... | ... |
### 次回プロジェクトへの提言
- ○○については、事前に△△を確認すること
- ...Mercariでは、プロジェクト完了時にSlackの会話ログからAIが自動的に知見レポートを生成し、Confluenceに保存する仕組みを導入したことが報告されています。
| 課題 | 影響 |
|---|---|
| マニュアルが古い・散在している | 新人が正しい情報にたどり着けない |
| 先輩社員に質問するハードルが高い | 「こんなこと聞いていいのか」と遠慮して学習が遅れる |
| 同じ質問が毎回繰り返される | 教える側の負担が増加 |
| 暗黙のルールが文書化されていない | 失敗して初めて学ぶ(コストが高い) |
新入社員専用のAIアシスタントをSlack上に構築します。
新入社員の質問(Slack DM or #onboarding チャンネル)
│
▼
AIアシスタント
├── ナレッジベース検索(公式ドキュメント)
├── FAQ検索(Slack会話から生成したFAQ)
├── 類似質問の過去回答を参照
└── 回答生成
│
├── 回答できた → 回答を送信 + 出典リンクを添付
└── 回答できない → 適切な担当者にエスカレーション| カテゴリ | 内容例 | データソース |
|---|---|---|
| 会社・組織 | 組織図、各部署の役割、主要メンバー | 公式ドキュメント |
| ツール・環境 | 各ツールの設定方法、アクセス権限の申請方法 | IT部門のFAQ + Slack会話 |
| 業務プロセス | 承認フロー、レポートの書き方、会議体の説明 | 公式マニュアル + Slack会話 |
| 暗黙のルール | 「この場合はこうする」「あのツールはこう使う」 | Slack会話から抽出したFAQ |
| 専門知識 | 業界用語、技術スタック、製品知識 | ドキュメント + Slack会話 |
ここが結構ミソなのですが、新人にとって最も助かるのは「暗黙のルール」です。公式マニュアルには載っていないが、チームでは当たり前になっている慣習——これこそがSlackの会話ログからAIで抽出すべき最も価値の高い情報です。詳しくは「RAGとは?社内データ活用で生成AIの精度を高める仕組みと導入方法」で解説しています。
| コンポーネント | 選択肢 | 特徴 |
|---|---|---|
| Embedding Model | OpenAI text-embedding-3-small / Cohere embed-v3 | テキストをベクトル化 |
| ベクトルDB | Pinecone / Weaviate / Qdrant / Chroma | ベクトル検索・保存 |
| LLM(回答生成) | Claude Sonnet / GPT-4o | 検索結果を基に回答を生成 |
| オーケストレーション | LangChain / LlamaIndex | RAGパイプラインの構築 |
[Slack Conversations API] → [メッセージ取得(日次バッチ)]
│
▼
[前処理] → メンション除去 / URL正規化 / Bot発言除外
│
▼
[チャンク分割] → スレッド単位でグルーピング
│
▼
[Embedding] → ベクトル化してDBに格納
│
▼
[メタデータ付与] → チャンネル名 / 投稿者 / 日時 / リアクション数Slack Conversations APIでメッセージを取得する際、以下の制限に注意が必要です。
| 制限 | 詳細 |
|---|---|
| レートリミット | Tier 3: 50リクエスト/分 |
| メッセージ取得 | 1回のAPIコールで最大200メッセージ |
| スレッド取得 | conversations.repliesで別途取得が必要 |
| 無料プランの制限 | 90日分のメッセージのみアクセス可能 |
Slack × AIのナレッジ管理には、以下の限界があります。率直に理解した上で導入を検討してください。
「CRM導入の現場で最も多い課題の一つが『属人化』です。特定のメンバーだけが知っている設定方法、過去の経緯、顧客への対応方針——これらがSlackに眠っている。AIでナレッジを形式知化する取り組みは、CRMの活用定着にも直結します。たとえばHubSpotの運用ノウハウをSlackからAIが自動抽出し、FAQとしてまとめれば、チーム全体の運用レベルが底上げされる。ナレッジ管理はAI時代の最優先インフラです。」
ナレッジの属人化は、CRMの活用定着を阻む最大の障壁の一つです。HubSpotゴールドパートナーのStartLinkでは、Slack×AIのナレッジ管理設計と、HubSpotのCRM活用定着を組み合わせた統合支援を提供しています。「属人化を解消してCRMの運用レベルを底上げしたい」という方は、ぜひご相談ください。
基本的な設計思想は同じです。Microsoft TeamsにもGraph APIを通じたメッセージ取得が可能で、RAGパイプラインの構築手法も同様に適用できます。ただし、API仕様やレートリミットの詳細が異なるため、ツールごとの技術的な調整は必要です。詳しくは「プロンプトエンジニアリング実践ガイド」で解説しています。
目安として、対象チャンネルに3ヶ月以上・1,000件以上のメッセージ蓄積がある状態が望ましいです。データ量が少ない場合、AIが十分なパターンを学習できず、生成されるFAQの品質が低くなります。
技術的には可能ですが、プライバシーの観点から慎重に判断する必要があります。対象チャンネルのメンバー全員の同意を得ること、データの利用目的を明示すること、分析対象から除外するチャンネルを設定できるようにすることを推奨します。
AIが生成したFAQやナレッジドキュメントを、Notion API / Confluence APIを通じて自動的に投稿する仕組みが一般的です。既存ドキュメントとの重複チェック、カテゴリ分類、公開前レビューのフローを組み込むことで、整合性を維持できます。
以下の指標を追跡することを推奨します。(1) 同じ質問の繰り返し発生回数の減少、(2) 新人の立ち上がり期間(入社から独力で業務遂行できるまでの日数)、(3) ナレッジベースの参照回数、(4) ベテラン社員への質問対応時間の削減。特に(1)と(2)は定量的に測定しやすい指標です。
株式会社StartLinkは、事業推進に関わる「販売促進」「DXによる業務効率化(ERP/CRM/SFA/MAの導入)」などのご相談を受け付けております。 サービスのプランについてのご相談/お見積もり依頼や、ノウハウのお問い合わせについては、無料のお問い合わせページより、お気軽にご連絡くださいませ。
