「AIを業務に導入したいが、GPT-4のAPI料金が月額数十万円になるのでは」――この懸念は、多くの中小企業がAI導入を躊躇する最大の理由のひとつです。しかし、すべての業務にGPT-4クラスのモデルが必要なわけではありません。定型的な分類、要約、情報抽出といったタスクであれば、パラメータ数が数十分の一の小規模言語モデル(SLM)で十分な精度を出せるケースが多いのです。詳しくは「ファインチューニングの企業活用ガイド」で解説しています。
本記事では、SLMの基本概念から具体的なモデル選定基準、企業での活用パターンまでを体系的に解説します。AI活用完全ガイドで、AI活用の全体像を把握できます。
この記事でわかること
AI導入のコスト負担を抑えつつ業務自動化を実現したい中小企業の経営者・技術責任者に向けた記事です。
- 小規模言語モデル(SLM)と大規模LLMの違いと使い分け基準 — 以下のタスクはSLMで十分な精度が得られるケースが多いです。
- 主要なSLMモデル(Phi-3、Gemma 2、Llama 3.2など)の特徴比較 — MicrosoftのPhi-3シリーズは、SLMの代名詞ともいえるモデルです。
- SLMをビジネスに活用する具体的なユースケースと導入パターン — カスタマーサポートの一次対応は、SLMが最も効果を発揮する領域のひとつです。
本記事では、SLMのコスト優位性や技術的な特徴をはじめ、実務で押さえておくべきポイントを体系的にまとめています。「大規模LLMの料金負担を軽減しつつ、AI活用を加速させたい」という方は、詳しくは「責任あるAI実装ガイド」で解説しています。
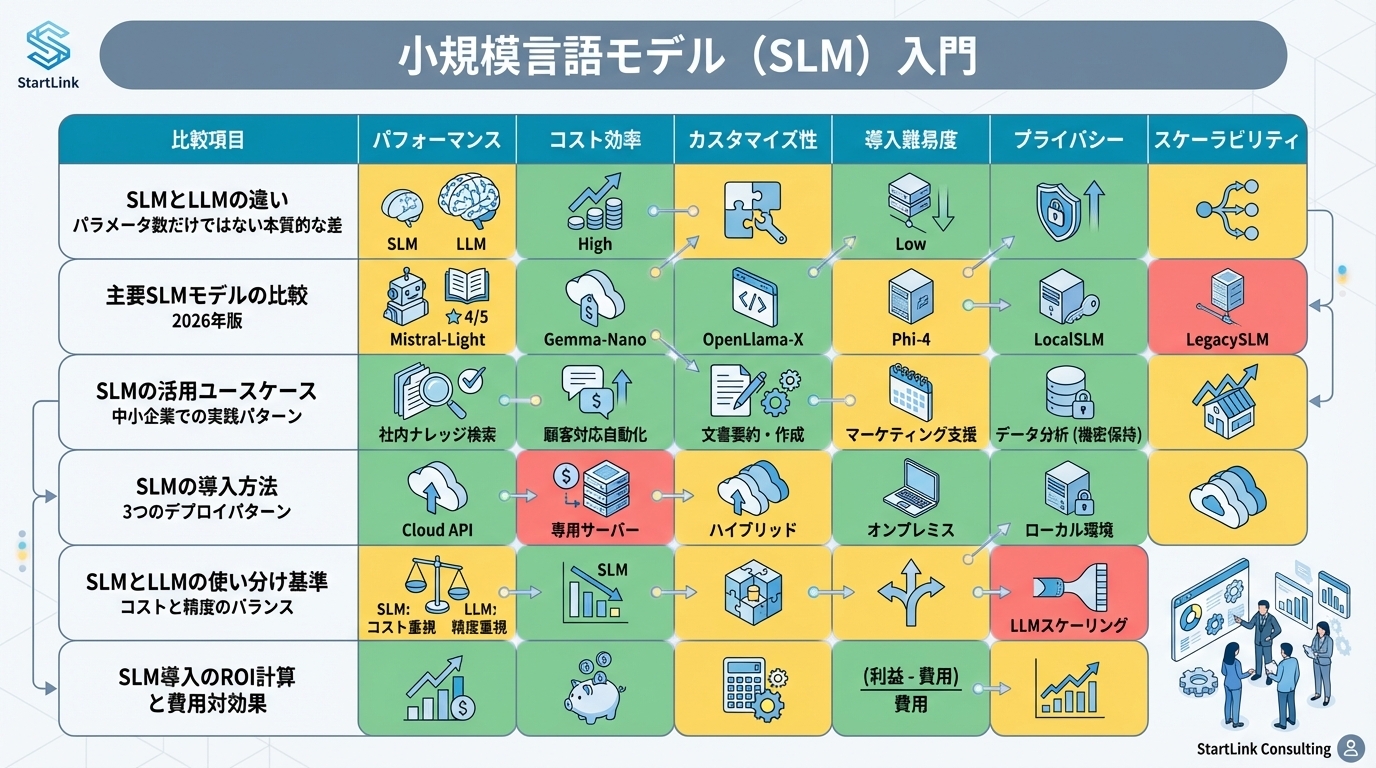
SLMとLLMの違い|パラメータ数だけではない本質的な差
パラメータ数による分類の基準
言語モデルの規模は、パラメータ数によって大まかに分類されます。
| 分類 |
パラメータ数 |
代表モデル |
推論コスト(目安) |
| 小規模(SLM) |
1B〜10B |
Phi-3 Mini、Gemma 2 2B |
月額数千〜数万円 |
| 中規模 |
10B〜70B |
Llama 3.1 70B、Mixtral 8x7B |
月額数万〜十数万円 |
| 大規模(LLM) |
70B以上 |
GPT-4、Claude 3 Opus |
月額数十万〜数百万円 |
ここで重要なのは、パラメータ数が多いほど「賢い」とは限らないことです。Microsoftが開発したPhi-3 Miniは3.8Bパラメータでありながら、いくつかのベンチマークでLlama 3 8Bに匹敵するスコアを記録しています。少ないパラメータでも、学習データの品質と学習手法の工夫次第で高い性能を発揮できるのです。詳しくは「RAG構築の実践ガイド」で解説しています。
コスト構造の違い
大規模LLMをAPI経由で利用する場合、トークン単価が高額になります。GPT-4 Turboの入力トークン単価は1Mトークンあたり10ドル前後ですが、Phi-3 MiniをAzure AI上で利用すれば、同等のタスクを10分の1以下のコストで処理できます。
自社サーバーやエッジデバイスでSLMを動作させれば、API利用料そのものがゼロになります。初期のハードウェア投資は必要ですが、月間数万件以上のリクエストがある場合、3〜6ヶ月でROIが逆転するケースが多いです。
応答速度とレイテンシ
SLMは推論に必要な計算量が少ないため、応答速度が圧倒的に速くなります。GPT-4が1リクエストあたり5〜15秒かかるのに対し、SLMをローカル環境で実行すれば1秒以内に応答を返せます。
チャットボットやリアルタイムの顧客対応では、この速度差がユーザー体験を大きく左右します。Google の調査によると、Webページの読み込みが3秒を超えると53%のユーザーが離脱するとされており、AI応答速度はビジネス成果に直結します。
主要SLMモデルの比較|2026年版
Microsoft Phi-3シリーズ
MicrosoftのPhi-3シリーズは、SLMの代名詞ともいえるモデルです。Phi-3 Mini(3.8B)、Phi-3 Small(7B)、Phi-3 Medium(14B)の3サイズが提供されており、用途に応じて選択できます。
Phi-3の最大の特徴は「教科書品質の合成データ」で学習されている点です。Webクロールで収集したノイズの多いデータではなく、構造化された高品質データで学習することで、少ないパラメータ数で高い推論能力を実現しています。Azure AI Studio、Ollama、ONNX Runtimeなど多様な環境で動作し、企業導入のハードルが低い点も強みです。
Google Gemma 2
Googleが公開したGemma 2は、2B・9B・27Bの3サイズが提供されています。特に2Bモデルは、スマートフォンやIoTデバイスでも動作可能な軽量さが特徴です。
Gemma 2はGoogleのDeepMind技術をベースにしており、推論効率が非常に高いです。Google Cloud Vertex AI上でのデプロイが容易で、すでにGoogle Workspaceを利用している企業にとっては、既存のインフラとの親和性が高い選択肢です。
Metaが公開したLlama 3.2には、1Bと3Bの小規模モデルが含まれています。オープンソースで商用利用可能な点が最大の強みで、ファインチューニングやカスタマイズの自由度が高いです。
Llama 3.2 3Bモデルは、テキスト要約・分類・情報抽出といった業務タスクで、GPT-3.5 Turboに近い精度を示すベンチマーク結果が報告されています。自社データでファインチューニングすれば、特定ドメインではさらに高精度なモデルを構築できます。ファインチューニングの具体的な方法は「ファインチューニング実践ガイド」で詳しく解説しています。
Apple OpenELMとその他の注目モデル
Apple が公開したOpenELMは、iPhoneやiPadなどのAppleデバイス上での動作を想定した超軽量モデルです。270M〜3Bのラインナップがあり、オンデバイスAIの実現に向けた重要な選択肢です。
その他にも、Alibaba Cloud のQwen2(0.5B〜72B)やStabilityAIのStableLM(1.6B〜12B)など、様々な企業・研究機関がSLMを公開しています。選択肢が多いため、自社の用途に合ったモデルを見極めることが重要です。
SLMの活用ユースケース|中小企業での実践パターン
ユースケース1: 問い合わせ対応の自動化
カスタマーサポートの一次対応は、SLMが最も効果を発揮する領域のひとつです。顧客からの問い合わせの70〜80%は、FAQ に記載済みの定型的な質問です。この定型応答をSLMに任せることで、人的リソースを複雑な問い合わせに集中させられます。
具体的な構成としては、Phi-3 MiniをRAG(Retrieval-Augmented Generation)と組み合わせる方法が有効です。社内のFAQデータベースやマニュアルをベクトル化し、問い合わせ内容に関連する情報を検索してからSLMに回答を生成させます。この構成であれば、GPT-4のAPIを呼び出す場合と比較して、月額コストを90%以上削減できます。
ユースケース2: 社内ドキュメントの要約・検索
社内に蓄積された議事録、提案書、報告書を要約・検索するタスクは、SLMで十分に対応可能です。ドキュメントを読み込んで「3行で要約して」「この報告書のリスク要因を抽出して」といったリクエストに応えるだけなら、3B〜7Bクラスのモデルで実用的な精度が出ます。
社内ドキュメントには機密情報が含まれるため、外部APIに送信したくないというニーズも多いです。SLMをオンプレミスで動かせば、データが社外に出ることなくAI活用を実現できます。ローカル環境でのLLM実行について詳しくは「ローカルLLM導入ガイド」をご覧ください。
ユースケース3: CRMデータの自動分類・タグ付け
HubSpot CRMに蓄積された商談メモや顧客フィードバックを自動分類するタスクにもSLMは有効です。たとえば、商談メモから「価格への懸念」「競合比較中」「導入時期未定」といったタグを自動付与することで、営業パイプラインの分析精度が向上します。
この用途では、自社の営業データでファインチューニングしたSLMが最も高い精度を発揮します。汎用LLMでは拾いきれない業界固有の表現やニュアンスを、自社データで学習させることで的確に分類できるようになります。
SLMの導入方法|3つのデプロイパターン
パターン1: クラウドAPI経由での利用
最も手軽なのは、Azure AI Studio、Google Cloud Vertex AI、Amazon Bedrockなどのクラウドプラットフォーム経由でSLMを利用する方法です。インフラ構築が不要で、即日利用を開始できます。Claude Codeを使った経営データの可視化にも、こうした考え方が反映されています。
Azure AI StudioではPhi-3シリーズが、Vertex AIではGemma 2が、それぞれマネージドサービスとして提供されています。GPT-4やClaude 3のAPIを利用する場合と比較して、トークン単価が大幅に安価です。
パターン2: オンプレミス・ローカル環境での実行
Ollama、llama.cpp、vLLMなどのツールを使えば、自社サーバーやローカルPCでSLMを実行できます。データが社外に出ないため、セキュリティ要件が厳しい業種(金融・医療・官公庁)に適しています。
必要なハードウェアスペックの目安は以下のとおりです。
| モデルサイズ |
必要GPU VRAM |
推奨GPU |
概算費用 |
| 1B〜3B |
4GB以上 |
NVIDIA RTX 3060 |
約5万円 |
| 7B〜8B |
8GB以上 |
NVIDIA RTX 4070 |
約10万円 |
| 13B〜14B |
16GB以上 |
NVIDIA RTX 4090 |
約25万円 |
量子化(Quantization)を適用すれば、必要なVRAMをさらに削減できます。4bit量子化を適用した7Bモデルであれば、4GBのVRAMでも動作可能です。
パターン3: エッジデバイスでの実行
スマートフォン、タブレット、IoTデバイスなどのエッジデバイスでSLMを実行するパターンです。ネットワーク接続が不安定な環境や、リアルタイム性が求められる用途に適しています。
AppleのCore ML、GoogleのMediaPipe、QualcommのAI Engineなどのフレームワークを使えば、モバイルデバイス上でSLMを動作させられます。建設現場での安全点検、物流倉庫でのピッキング指示、店舗での接客支援など、現場で即座にAI推論が必要なシーンで威力を発揮します。
SLMとLLMの使い分け基準|コストと精度のバランス
SLMが適するタスク
以下のタスクはSLMで十分な精度が得られるケースが多いです。
- テキストの分類・カテゴリ分け(感情分析、問い合わせ種別の判定)
- 定型フォーマットへの情報抽出(請求書からの金額・日付の抽出)
- 短文の要約(メール要約、チャット要約)
- FAQ応答(定型的な質問への回答生成)
- コードの補完・簡単な生成(定型的なスクリプト生成)
LLMが必要なタスク
以下のタスクは、大規模LLMの方が明らかに優れた結果を出します。
- 長文の構造的な執筆(5,000字以上のレポート、記事作成)
- 複雑な推論を伴う分析(多段階の論理展開、因果関係の特定)
- マルチモーダルな処理(画像+テキストの複合的な理解)
- 高度なコード生成(大規模システムの設計・実装)
- 創造的な文章生成(マーケティングコピー、ブランドストーリー)
ハイブリッド構成の推奨
実務では、SLMとLLMを組み合わせた「ハイブリッド構成」が最もコスト効率に優れます。具体的には、まずSLMで一次処理(分類・抽出・簡易応答)を行い、SLMで対応できない複雑なリクエストのみをLLMにエスカレーションする構成です。
たとえばカスタマーサポートでは、SLMが問い合わせを分類し、定型的な質問にはSLMが直接回答、複雑な質問や感情的なクレームのみをGPT-4に転送するというフローが考えられます。この構成にすることで、LLMのAPI利用量を70〜80%削減しつつ、顧客満足度を維持できます。
SLM導入のROI計算と費用対効果
コスト比較シミュレーション
月間10万件のテキスト分類タスクを処理する場合のコスト比較を示します。
| 方式 |
月額コスト(概算) |
応答速度 |
データセキュリティ |
| GPT-4 API |
約30万〜50万円 |
3〜10秒 |
データが外部に送信される |
| GPT-3.5 Turbo API |
約3万〜5万円 |
1〜3秒 |
データが外部に送信される |
| SLM(クラウド) |
約1万〜3万円 |
0.5〜2秒 |
クラウド事業者に依存 |
| SLM(オンプレミス) |
初期投資のみ(電気代月数千円) |
0.1〜1秒 |
データが社外に出ない |
月間10万件規模のタスクであれば、SLMのオンプレミス運用に切り替えるだけで年間数百万円のコスト削減が可能です。
導入前に確認すべきポイント
SLM導入を検討する際は、以下の点を事前に確認しましょう。
- 対象タスクの複雑さ: SLMで十分な精度が出るか、プロトタイプで検証する
- 月間リクエスト数: 少量ならAPI利用の方がコスト効率が良い場合もある
- セキュリティ要件: 機密データを扱うならオンプレミス運用を検討する
- 運用体制: モデルの更新・監視を担当できる人材がいるか
あわせて読みたい
まとめ
- 小規模言語モデル(SLM)は、大規模LLMの「高すぎる・遅い・データを外部に出したくない」という3つの課題を解決する選択肢です
- Phi-3、Gemma 2、Llama 3.2など、高品質なオープンソースSLMが次々と公開されており、中小企業でも実用的なAI活用が手の届く範囲に入っています
- このテーマの全記事はAIテックトレンドガイドでご覧いただけます
- すべてのタスクにGPT-4クラスのLLMを使う必要はありません
- 定型的な業務にはSLMを、創造的・複雑な業務にはLLMを使い分けるハイブリッド構成が、コスト効率と精度の両立を実現する最適解です
HubSpotゴールドパートナーのStartLinkでは、HubSpot CRMとAIモデルを連携させた業務自動化の支援を行っています。「どのモデルを選べばよいか」「自社データでのファインチューニングは可能か」といったご相談も承っています。AIコスト最適化をお考えの方は、お気軽にお問い合わせください。
よくある質問(FAQ)
Q1: SLMを導入するのに専門的なAI知識は必要ですか?
クラウドAPI経由であれば、REST APIを呼び出せるレベルの技術力で利用開始できます。Azure AI StudioやVertex AIにはGUI操作でモデルをデプロイできる機能もあり、専門知識がなくても導入可能です。オンプレミス運用の場合は、サーバー管理とPythonの基本的なスキルが必要になります。
Q2: SLMの精度はどのくらいですか?大規模LLMと比べて劣りますか?
タスクの種類によります。テキスト分類や情報抽出のような定型タスクでは、SLMでも90%以上の精度を出せるケースが多いです。一方、複雑な推論や長文生成ではLLMに劣ります。導入前にプロトタイプで精度検証を行い、許容できる精度かどうかを確認することを推奨します。
Q3: SLMとLLMを併用する場合、どのように切り替えますか?
一般的な方法は「ルーティング」です。入力テキストの長さや複雑さをSLMで事前判定し、簡単なリクエストはSLMが処理、複雑なリクエストはLLMのAPIに転送する仕組みを構築します。この振り分けロジック自体をSLMで実行するのが効率的です。
Q4: 日本語の精度は英語と比べてどうですか?
SLMは学習データに占める日本語の割合が少ないため、英語と比較すると日本語の精度はやや低い傾向にあります。ただし、日本語データでファインチューニングを行えば大幅に改善できます。Llama 3.2やQwen2は日本語対応が比較的良好で、日本語のベンチマークでも高いスコアを記録しています。
Q5: SLMのモデルはどのくらいの頻度で更新されますか?
主要なSLMモデルは3〜6ヶ月ごとに新バージョンがリリースされる傾向にあります。ただし、自社でファインチューニングしたモデルは、ベースモデルの更新に合わせて再学習が必要になる場合があります。モデルの更新計画を含めた運用設計を事前に行うことが重要です。