マルチエージェントAIの核心は「役割分業」にあります。1つのAIに全てを任せるのではなく、コード生成・レビュー・テスト・ドキュメント作成を専門エージェントに分けることで、品質と処理速度が劇的に向上します。
「1つのAIエージェントに全てを任せていたが、指示が複雑になるほど品質が落ちる」「コード生成もレビューもドキュメント作成も同じAIで済ませたいが、中途半端な結果しか返ってこない」——AIエージェント活用が本格化するにつれ、こうした声が増えてきました。
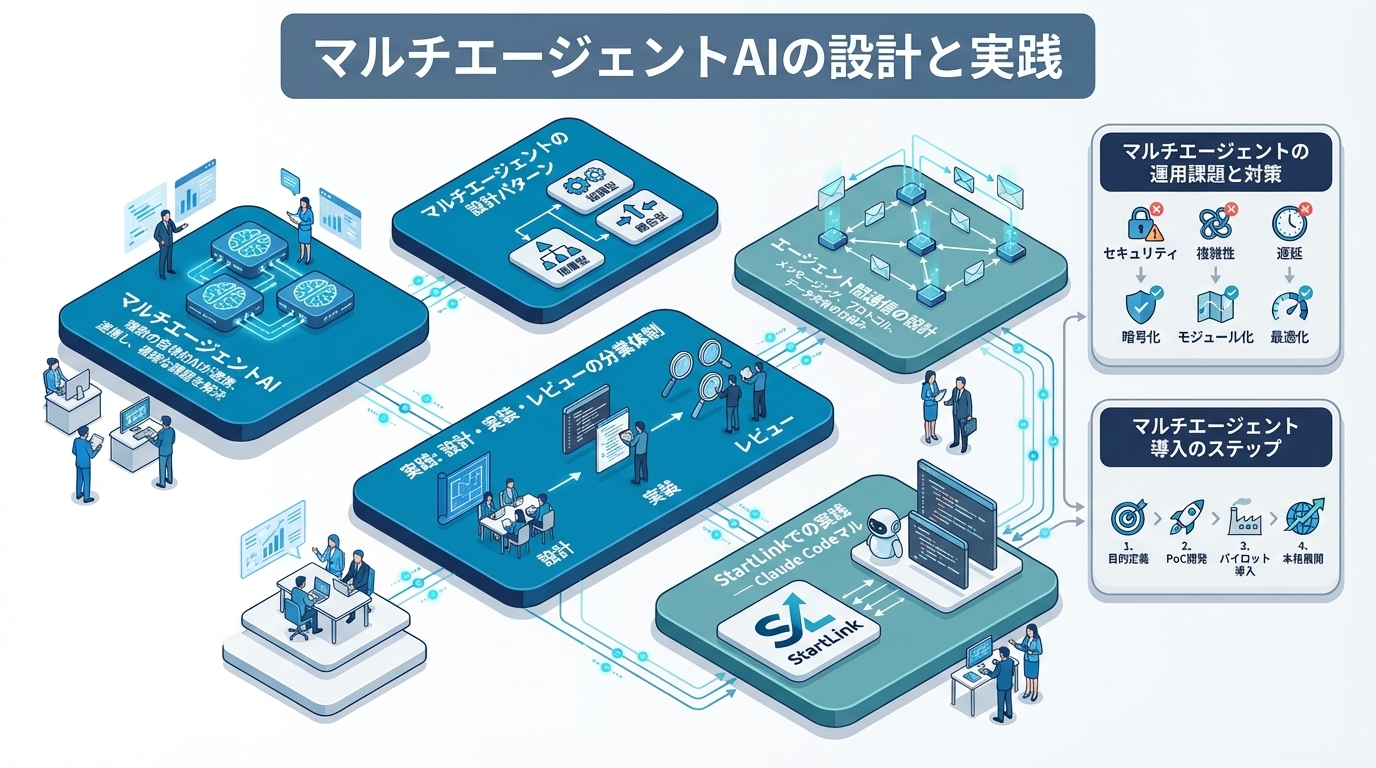
マルチエージェントAIは、役割分担された複数のAIエージェントが協調してタスクを処理する設計パターンです。Anthropicが提唱する「Orchestrator-workers」のように、司令塔と実行者を分けることで、シングルエージェントが抱える3つの課題——コンテキストウィンドウの制約、タスクの専門性のジレンマ、処理速度のボトルネック——を構造的に解消できます。
本記事では、マルチエージェントAIの基本概念と必要になる場面から、オーケストレーター型・パイプライン型・議論型の設計パターン、そして本番運用に必要な品質管理・障害対応のノウハウまでを解説します。
この記事でわかること
複数AIエージェントの連携設計を検討している技術リーダー・DX推進担当者に向けた記事です。
- マルチエージェントAIの基本と必要になる場面 — 1つのAIでは対応しきれない課題と、複数AI連携で解決できる理由を解説します
- 複数AIの役割分担・並列処理の設計パターン — 司令塔と実行者の関係など、AIエージェント間の連携設計を紹介します
- 本番運用に必要な品質管理・障害対応のノウハウ — 個別のAIが障害を起こした場合のリカバリー設計など、実践的なポイントを解説します
AI活用の成否は、技術の理解だけでなく、業務への落とし込み方で決まります。本記事では、実務で成果を出すための具体的なアプローチを解説していますので、
マルチエージェントAIとは何か
シングルエージェントの限界とマルチエージェントの必要性
AIエージェントの活用が進む中で、「1つのAIエージェントにすべてを任せる」アプローチの限界が明らかになってきました。シングルエージェント(1つのAIインスタンスが全タスクを処理する構成)には、以下の課題があります。
コンテキストウィンドウの制約: 現在のLLMにはコンテキストウィンドウ(一度に処理できる情報量)に上限があります。Claude 3.5 Sonnetで200Kトークン、GPT-4oで128Kトークンです。複雑なプロジェクト(大規模なコードベース、膨大なドキュメント群)では、すべての情報を1つのエージェントに渡すことが物理的に不可能になります。
タスクの専門性のジレンマ: 1つのエージェントに「コードを書いて」「レビューもして」「ドキュメントも書いて」「テストも走らせて」と依頼すると、指示が複雑になるほど各タスクの品質が低下します。人間のチームと同じように、役割を分けた方が各タスクの品質は向上します。
処理速度のボトルネック: シングルエージェントでは、タスクは必ず逐次処理になります。タスクAが終わるまでタスクBに着手できないため、大量のタスクがある場合に処理時間が膨大になります。
マルチエージェントAIシステムは、これらの課題を「複数のAIエージェントを協調させる」ことで解決します。
マルチエージェントAIの定義
マルチエージェントAIシステムとは、複数のAIエージェントが明確な役割分担のもとで協調し、共通の目標を達成するシステムです。各エージェントは特定のタスクに特化し、エージェント間の情報共有とタスク調整を行う仕組み(オーケストレーション)が全体を統制します。Anthropic社は2025年1月に公開したガイド「Building effective agents」の中で、マルチエージェントパターンを「Orchestrator-workers」として定義しています。オーケストレーター(指揮者)がタスクを分解し、複数のワーカー(実行者)に割り振り、結果を統合するパターンです。マルチエージェントの概念をより深く理解するためには、エージェンティックワークフロー全体の設計が重要です。「エージェンティックワークフロー設計ガイド|AIエージェントの業務自動化を実現する方法」も合わせて参照してください。
HubSpot ゴールドパートナーが開発・提供
HubSpotとNotionを併用している場合、HubSpotゴールドパートナーのStartLinkが開発した連携アプリ「Sync for Notion」を使うと、HubSpotのCRM画面からNotionのページやデータベースを直接作成・編集・参照できます。議事録やナレッジをコンタクト・取引に紐づけて管理したい企業に適しています。詳細はSync for Notionをご覧ください。
マルチエージェントの設計パターン
パターン1: オーケストレーター型(Orchestrator-Workers)
最も基本的で汎用性の高いパターンです。1つのオーケストレーターエージェントが全体を統制し、複数のワーカーエージェントがタスクを実行します。
構成要素
- オーケストレーター: タスクの分解、ワーカーへの割り振り、結果の統合、品質判定を担当
- ワーカー群: それぞれ特定のタスク(コーディング、レビュー、テスト、ドキュメント作成等)に特化
動作フロー
- オーケストレーターがユーザーの依頼を受け取る
- 依頼を複数のサブタスクに分解する
- 各サブタスクを適切なワーカーに割り振る
- ワーカーがタスクを実行し、結果をオーケストレーターに返す
- オーケストレーターが結果を統合し、品質を確認する
- 品質が基準を満たさない場合、該当ワーカーに再実行を指示する
このパターンは、ソフトウェア開発の分業体制に特に適しています。たとえば、オーケストレーターが「ログイン機能の実装」という依頼を受けると、設計ワーカーにDB設計を、実装ワーカーにコーディングを、テストワーカーにテストコード作成を並列で依頼し、最後にレビューワーカーが全体の整合性を確認する――という流れです。
パターン2: パイプライン型(Sequential Chain)
タスクが明確な順序で処理される場合に適したパターンです。各エージェントが工程の1ステップを担当し、前のエージェントの出力が次のエージェントの入力になります。
適用例: コンテンツ制作パイプライン
- リサーチエージェント: キーワード分析・競合調査・情報収集を行い、構成案を出力
- ライティングエージェント: 構成案をもとに記事本文を執筆
- レビューエージェント: 記事の品質をスコアリングし、基準未達なら修正指示を出力
- 公開エージェント: 品質基準を満たした記事をCMSに公開
パイプライン型の利点は、各工程のエージェントを独立して改善できることです。レビュー精度を上げたければレビューエージェントだけを改善すればよく、他のエージェントに影響を与えません。
パターン3: 議論型(Debate / Adversarial)
複数のエージェントが異なる立場からタスクに取り組み、相互チェックによって品質を高めるパターンです。
構成例
- 提案エージェント: ソリューションを提案する
- 批判エージェント: 提案のリスク・欠陥・改善点を指摘する
- 仲裁エージェント: 両者の意見を統合し、最終判断を下す
Google DeepMindの研究(2024年)では、議論型マルチエージェントを使った数学問題の解答精度が、シングルエージェントに比べて15%向上したと報告されています。
ビジネスでの活用例としては、戦略提案書の作成があります。1つのエージェントが戦略案を起案し、別のエージェントがリスクと課題を指摘し、3つ目のエージェントが両者を踏まえた最終版を作成する――というフローです。
パターン4: 自律分散型(Autonomous Swarm)
各エージェントが自律的に動き、共有メモリ(ファイルシステム、データベース等)を通じて間接的に協調するパターンです。明確なオーケストレーターは存在せず、各エージェントがルールに従って自律的に行動します。
このパターンは最も高度で、以下の条件が揃う場合に適しています。
- タスクが明確に分離可能で、エージェント間の依存関係が少ない
- 各エージェントが自律的に判断できるルールセットがある
- 共有メモリへのアクセス制御が適切に設計されている
実践: 設計・実装・レビューの分業体制
設計エージェントの役割と設定
設計エージェントは、プロジェクト全体の構造設計を担当します。具体的には、アーキテクチャ設計、データモデル設計、API設計、タスクの分解と依存関係の整理を行います。
設計エージェントに求められる能力は以下の通りです。
- 全体俯瞰力: プロジェクト全体の構造を把握し、一貫性のある設計を行う
- タスク分解力: 大きな目標を、実装可能な粒度のタスクに分解する
- 仕様書作成力: 実装エージェントが迷わない程度に詳細な仕様書を生成する
設計エージェントの出力(仕様書・タスクリスト・設計図)は、共有メモリに保存され、実装エージェントがこれを参照して作業を進めます。
実装エージェントの並列運用
実装エージェントは、設計エージェントが作成したタスクリストに基づいてコードを書くエージェントです。マルチエージェント構成の最大のメリットは、複数の実装エージェントを並列に走らせることで、開発速度を大幅に向上させられることです。
並列化の条件: タスク間に依存関係がないこと。たとえば「ログイン機能」と「ダッシュボード画面」は並列に実装可能ですが、「ログイン機能」と「ログイン後のリダイレクト処理」は逐次的に進める必要があります。設計エージェントがタスクの依存関係を明示することで、並列化可能なタスクを特定できます。
マルチエージェント環境では、各エージェントがMCP(Model Context Protocol)を活用して外部ツールに接続し、freeeやHubSpotなどのビジネスツールを横断的に操作する構成も実現可能です。
ファイル競合の回避: 複数の実装エージェントが同じファイルを同時に編集すると、変更が衝突するリスクがあります。これを防ぐためには、以下の方策が有効です。
- 各エージェントの担当ファイルを事前に明確に分離する
- 共有ファイル(設定ファイル、定数定義など)への書き込みは1つのエージェントに限定する
- Gitブランチを分けて並列作業し、マージ時に統合する
レビューエージェントの品質保証機能
レビューエージェントは、実装エージェントの出力(コード、コンテンツ等)の品質を検証する「品質ゲート」として機能します。
レビューエージェントの設計で重要なのは、「実装エージェントとは異なるコンテキストで動作する」ことです。同じAIインスタンスが書いたコードを同じインスタンスがレビューしても、自分のバイアスに気づきにくい構造的な問題があります。レビューエージェントを別インスタンスとして独立させることで、より客観的なレビューが可能になります。
レビューエージェントが確認すべき観点は以下の通りです。
- 機能要件: 仕様書通りに実装されているか
- コード品質: 命名規則、ファイル構成、関数の複雑度
- セキュリティ: 認証情報のハードコード、SQLインジェクション等の脆弱性
- テスト: テストカバレッジ、エッジケースの考慮
- パフォーマンス: 明らかなN+1クエリ、不要なリソース消費
エージェント間通信の設計
共有メモリ方式 vs メッセージパッシング方式
マルチエージェント間の情報共有には、大きく2つの方式があります。
共有メモリ方式: ファイルシステムやデータベースに情報を書き込み、他のエージェントがそれを読み取る方式です。実装がシンプルで、エージェントの追加・削除も容易です。
メリット:
- エージェント間の結合度が低く、独立性が高い
- 情報が永続化されるため、エージェントの再起動後も状態を復元できる
- 新しいエージェントを追加する際、既存のエージェントを変更する必要がない
デメリット:
- 同時書き込みによるファイル競合のリスクがある
- リアルタイムの双方向通信には向かない
メッセージパッシング方式: エージェント間で直接メッセージを送受信する方式です。リアルタイム性が高く、複雑な対話が可能です。
メリット:
- リアルタイムの双方向通信が可能
- 複雑な対話や交渉ができる
デメリット:
- エージェント間の結合度が高くなる
- メッセージの送受信の管理が複雑になる
実務では、共有メモリ方式が多く採用されています。特にファイルシステムを共有メモリとして使う方法は、セットアップが容易で、人間がエージェントの出力を確認しやすいという利点があります。
同期ファイルの設計パターン
共有メモリ方式でマルチエージェントを運用する場合、「同期ファイル」の設計が重要です。同期ファイルとは、エージェント間で状態や進捗を共有するためのファイルです。
同期ファイルに含めるべき情報は以下の通りです。
- 各エージェントの現在の状態: 「作業中」「待機中」「完了」「エラー」
- 担当タスクの割り当て: どのエージェントがどのタスクを担当しているか
- 完了したタスクの一覧と結果サマリー
- 他のエージェントへの申し送り事項
同期ファイルの更新ルールも重要です。「書き込む前に必ず最新版を読む」「同じセクションを同時に編集しない」といったルールを、エージェントの指示文(CLAUDE.md等)に明記しておく必要があります。
実践事例 ── Claude Codeマルチエージェント運用
複数Claude Codeインスタンスの並列運用
先進的な開発チームでは、複数のClaude Codeインスタンスを並列で運用し、設計・実装・レビューの分業体制をAIで構築する事例が増えています。こうしたClaude Codeの活用に関心のある方は、経営データの可視化やコンテンツマーケティングの効率化もぜひご覧ください。
この体制では、各エージェントが同じリポジトリ上で作業しつつ、担当領域を明確に分離します。ファイルシステムを共有メモリとして使い、同期ファイルで各エージェントの状態と作業進捗を管理する方式です。
効果として実感しているのは以下の点です。
- 開発速度の向上: 独立性の高いタスクを複数エージェントで並列処理することで、逐次処理に比べて開発速度が大幅に向上しています
- 品質の安定化: 実装エージェントとレビューエージェントを分離することで、セルフレビューでは見逃しがちな問題を検出できるようになりました
- コンテキスト管理の改善: 各エージェントが特定の領域に集中するため、コンテキストウィンドウの制約による品質低下が軽減されています
AIエージェントの開発手法全般については、「AIエージェント開発ガイド|設計から実装・デプロイまでの実践手順」で詳しく解説しています。
運用で学んだ教訓
マルチエージェント運用を実践する中で得られた重要な教訓があります。
教訓1: 指示文の精度がすべてを左右する
各エージェントへの指示文(システムプロンプトやCLAUDE.mdに相当するもの)の精度が、マルチエージェントシステム全体の品質を決定します。曖昧な指示は、エージェント間の認識齟齬を生み、手戻りや品質低下につながります。指示文には「やること」だけでなく「やらないこと」「判断に迷ったときの行動規範」も明記することが重要です。
教訓2: エージェントの数は少なく始める
最初から多数のエージェントを投入するのではなく、2〜3体から始めて段階的に増やすアプローチが効果的です。エージェント数が増えると、調整コスト(同期、競合回避、品質統制)も増大するため、少数で運用パターンを確立してからスケールさせることを推奨します。
教訓3: 人間の監視ポイントを設計に組み込む
完全自律ではなく、人間がチェックポイントで確認を入れる「ヒューマン・イン・ザ・ループ」の設計が、本番運用では不可欠です。特に、外部への公開物(記事、コード、メール等)を最終的に承認するフェーズには、必ず人間のレビューを入れるべきです。
マルチエージェントの運用課題と対策
障害対応とリカバリー
マルチエージェントシステムでは、個別のエージェントが障害を起こした場合のリカバリー設計が重要です。
エージェントの障害パターン
- タイムアウト: エージェントが長時間応答しない場合、タイムアウト閾値を設定し、別のエージェントに再割り当てする
- 出力の品質劣化: エージェントの出力品質が一定基準を下回った場合、そのエージェントのコンテキストをリセット(新しいインスタンスを起動)する
- ファイル競合: 複数エージェントが同じファイルを編集してしまった場合、最新のタイムスタンプの変更を採用し、他のエージェントに再作業を依頼する
リカバリー設計のポイント
- 各エージェントのタスクはべき等(idempotent)に設計する。つまり、同じタスクを再実行しても問題ない設計にする
- 中間成果物を共有メモリに保存しておくことで、障害発生時に途中から再開できるようにする
- オーケストレーターにリトライロジックを組み込み、一定回数の失敗後にアラートを出す
スケーリングの考え方
マルチエージェントシステムのスケーリングでは、単にエージェント数を増やせばよいわけではありません。
スケーリングの原則
| エージェント数 |
適用シーン |
注意点 |
| 2〜3体 |
小規模プロジェクト、初期導入 |
調整コストが低く、運用が安定しやすい |
| 4〜6体 |
中規模プロジェクト、複数領域の並列作業 |
同期ファイルの設計と競合回避が重要になる |
| 7体以上 |
大規模プロジェクト、24時間自動運用 |
オーケストレーターの設計が複雑化。段階的な拡張を推奨 |
エージェント数を増やす際は、「アムダールの法則」に注意してください。タスクの中に並列化できない部分(逐次処理が必須の工程)があると、エージェント数を増やしても速度向上は頭打ちになります。ボトルネックの工程を特定し、そこを解消してからスケールさせることが重要です。
マルチエージェント導入のステップ
ステップ1: 分業設計から始める
マルチエージェントの導入は、まず「どのタスクをどう分割するか」の設計から始めます。
既存の業務フローを分析し、以下の基準でタスクを分類します。
- 並列化可能なタスク: 他のタスクに依存せず、独立して実行可能
- 逐次処理が必要なタスク: 前のタスクの出力が入力になる
- レビューが必要なタスク: 品質チェックポイントを設ける必要がある
この分類をもとに、オーケストレーター型・パイプライン型・議論型のうち、最適なパターンを選択します。
ステップ2: 2体構成から始める
最初のマルチエージェント構成は「実装エージェント + レビューエージェント」の2体構成を推奨します。
この構成では、実装エージェントがタスクを実行し、レビューエージェントが品質を検証します。シンプルですが、「別のAIインスタンスがチェックする」ことで、シングルエージェントでは検出できなかった問題を発見でき、品質が向上します。
2体構成で安定した運用ができることを確認してから、設計エージェント、テストエージェントなどを段階的に追加していきます。
ステップ3: 同期ルールとモニタリングの整備
エージェント数を増やす前に、以下の基盤を整備します。
- 同期ファイルのフォーマット: エージェント間で共有する情報のフォーマットを標準化する
- 競合回避ルール: 同じファイルを同時に編集しないためのルールを明文化する
- モニタリング: 各エージェントの実行状況、エラー率、品質スコアを可視化する仕組みを構築する
HubSpot ゴールドパートナーが開発・提供
HubSpotと会計ソフトの連携には、HubSpotゴールドパートナーのStartLinkが開発する連携アプリが利用できます。freee会計とはSync for freee、マネーフォワード クラウドとはSync for Money Forwardで、取引情報からの見積書・請求書作成や取引先・品目の同期が可能です。主要なクラウド会計ソフトの双方に対応しているため、経理体制に合わせて選択できます。
まとめ ── マルチエージェントAIは「AIチーム」の時代を拓く
- マルチエージェントAIは、「1つのAIに全部やらせる」時代から「複数のAIを協調させてチームとして機能させる」時代への移行を象徴する技術です
- このテーマの全記事はAIエージェント運用ガイドでご覧いただけます
- 設計パターン(オーケストレーター型・パイプライン型・議論型・自律分散型)を理解し、自社の業務に最適なパターンを選択すること
- まずは2体構成から始め、安定した運用パターンを確立してからスケールさせること
- そして、人間のチェックポイントを設計に組み込むこと――これらが、マルチエージェントAIを成功させるための鍵です
AIエージェントの活用をさらに深めたい方は、CRM特化型コンサルティングとAI活用アドバイザリーの実績を持つHubSpotゴールドパートナーの株式会社StartLinkにお気軽にご相談ください。
よくある質問(FAQ)
Q1. マルチエージェントAIを導入するのに、専門的なエンジニアリングスキルは必要ですか?
マルチエージェントの構成は、使用するツールによって難易度が異なります。Claude Codeを使った構成であれば、ターミナルの基本操作ができれば導入可能です。複数のClaude Codeインスタンスを同じプロジェクトディレクトリで起動し、各インスタンスに異なる指示を与えるだけで、基本的なマルチエージェント構成が実現できます。本格的なオーケストレーション(自動的なタスク割り振り、障害リカバリー等)を実装する場合は、Python等でのスクリプト作成スキルが必要になります。
Q2. マルチエージェントのコストはシングルエージェントの何倍くらいになりますか?
エージェント数に比例してAPI利用料は増加しますが、「時間あたりのアウトプット」で見ると、コスト効率は向上するケースが多いです。たとえば3体のエージェントを並列で動かした場合、API利用料は約3倍になりますが、処理時間は3分の1に短縮されるため、「1タスクあたりのコスト」は同等か、品質向上分を考慮するとむしろ改善されます。Claude Codeのような定額プランを利用している場合は、追加コストなしで並列運用が可能です。
Q3. マルチエージェントは小規模な会社でも活用できますか?
はい。むしろ小規模な組織ほどメリットが大きい場合があります。人手が少ない組織では、1人のエンジニアや経営者が複数の役割を兼任していることが多く、マルチエージェントは「AIによる仮想チームの構築」として機能します。少数精鋭でのAI経営については「少数精鋭企業×AI活用ガイド」で詳しく解説しています。設計・実装・レビューをそれぞれ別のAIエージェントに任せることで、実質的に3人分の開発チームを確保できます。
Q4. エージェント同士が矛盾した判断をした場合、どう解決しますか?
オーケストレーター型の構成では、オーケストレーターが最終判断を下します。議論型の構成では、仲裁エージェントが両者の意見を統合します。いずれの場合も、判断基準を事前にルール化しておくことが重要です。「セキュリティに関する指摘は常に優先する」「パフォーマンスとコードの可読性が競合する場合は可読性を優先する」といったルールを明文化しておくことで、矛盾の解消が自動化されます。
Q5. マルチエージェントの成果物の著作権やライセンスはどうなりますか?
AIが生成した成果物の著作権は、2026年3月時点では法的に明確な結論が出ていない部分があります。日本の著作権法では「思想又は感情を創作的に表現したもの」が著作物とされており、AIが自律的に生成したものは著作物に該当しないという見解が主流です。ただし、人間が詳細な指示を出し、AIの出力を選択・編集した場合は、人間の創作物として認められる可能性があります。業務利用する場合は、社内の法務担当や弁護士に確認することを推奨します。
あわせて読みたい