title: "RAGとは?社内データ活用で生成AIの精度を高める仕組みと導入方法"
slug: "hubspot-ai/genai-basics/rag-enterprise-knowledge-guide"
metaDescription: "RAG(検索拡張生成)の仕組みと企業での社内ナレッジ活用への応用方法を解説。ハルシネーション対策としてのRAG導入ステップ、ベクトルDBの選び方、成功事例を紹介します。"
featuredImage: "https://www.start-link.jp/hubfs/blog-featured-images/ai.webp"
blogAuthorId: "166212808307"
contentGroupId: "166203508570"
keywords: ["RAG", "RAG とは", "社内データ AI活用"]
category: "BD_genai-basics"
「ChatGPTは便利だが、自社の製品情報や社内規程について正確に回答できない」――この課題を解決する技術がRAG(Retrieval-Augmented Generation:検索拡張生成)です。
RAGは、生成AIが回答を生成する前に、社内のドキュメントやナレッジベースから関連情報を検索・取得し、それを根拠として回答する仕組みです。これにより、生成AIの最大の弱点であるハルシネーション(事実と異なる回答の生成)を大幅に抑制できます。
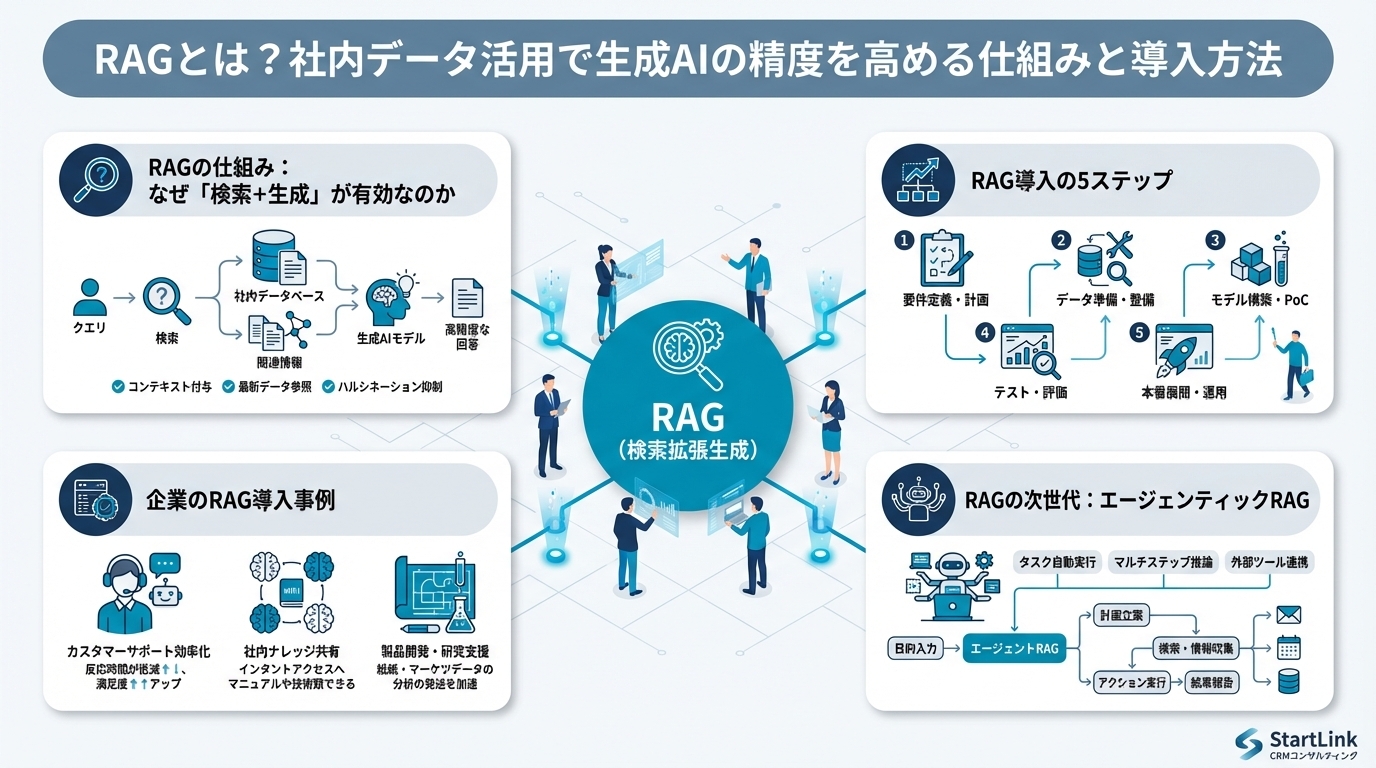
RAGの仕組み:なぜ「検索+生成」が有効なのか
RAGのアーキテクチャは、大きく3つのステップで構成されます。
| ステップ | 処理内容 | 技術要素 |
|---|---|---|
| 1. 検索(Retrieval) | ユーザーの質問に関連するドキュメントを検索 | ベクトル検索・セマンティック検索 |
| 2. 拡張(Augmentation) | 検索結果をLLMのプロンプトに付与 | コンテキストウィンドウへの挿入 |
| 3. 生成(Generation) | 検索結果を根拠に回答を生成 | LLM(GPT-4o、Claude等) |
従来の生成AIは学習データのみに依存するため、学習データに含まれない最新情報や社内固有の知識には対応できません。RAGは「必要な情報を都度検索してからAIに渡す」ことで、この限界を克服します。
ファインチューニングとの違い
社内データをAIに反映させる方法としては、RAGのほかにファインチューニング(追加学習)があります。
| 比較項目 | RAG | ファインチューニング |
|---|---|---|
| データ更新の反映速度 | リアルタイム反映可能 | 再学習が必要(数時間〜数日) |
| コスト | 検索基盤の構築費用 | GPU計算コスト(高額) |
| 情報の正確性 | 出典を明示可能 | ハルシネーションのリスクあり |
| 適するユースケース | FAQ・社内問い合わせ・ドキュメント検索 | 専門用語・文体の学習 |
| 導入難易度 | 中(ベクトルDB+検索パイプライン) | 高(ML基盤+学習データ整備) |
多くの企業ユースケースでは、RAGが費用対効果の面で優れています。
RAG導入の5ステップ
ステップ1:対象ドキュメントの棚卸し
RAGに取り込む社内ドキュメントを特定します。製品マニュアル、FAQ、社内規程、営業資料、議事録など、問い合わせ頻度が高い情報から優先的に対象とします。
ステップ2:ベクトルデータベースの選定
ドキュメントをベクトル化して格納するデータベースを選定します。
| ベクトルDB | 特徴 | 料金体系 |
|---|---|---|
| Pinecone | フルマネージド・高速 | 従量課金 |
| Weaviate | オープンソース・マルチモーダル対応 | セルフホスト無料 |
| Qdrant | 高パフォーマンス・Rust製 | セルフホスト無料 |
| pgvector | PostgreSQL拡張・既存DB活用可 | PostgreSQL費用のみ |
| Supabase Vector | pgvector+マネージド環境 | Supabase料金に含む |
既にPostgreSQLを利用している企業は、pgvectorの導入が最もスムーズです。
ステップ3:チャンキングとエンベディング
ドキュメントを適切なサイズの「チャンク」に分割し、エンベディングモデルでベクトル化します。チャンクサイズの目安は500〜1,000トークンで、セクション単位の分割が推奨されます。
ステップ4:検索パイプラインの構築
ユーザーの質問に対して最も関連性の高いチャンクを検索するパイプラインを構築します。ハイブリッド検索(ベクトル検索+キーワード検索の組み合わせ)が精度向上に有効です。
ステップ5:回答生成と評価
検索されたチャンクをLLMに渡して回答を生成し、出典情報を付与します。回答精度はRAGAS(RAG Assessment)フレームワークなどで定量評価できます。
企業のRAG導入事例
パナソニック コネクト
パナソニック コネクトは、社内の技術ドキュメント検索にRAGを導入。約3万件の技術資料をベクトル化し、エンジニアの情報検索時間を60%削減しました(2024年発表)。
ベネッセホールディングス
ベネッセは、教育コンテンツのカスタマーサポートにRAGベースのAIチャットボットを導入。回答精度は95%以上を達成し、オペレーターへのエスカレーション率を40%削減しました。
RAGの次世代:エージェンティックRAG
2025年以降のトレンドとして、RAGとAIエージェントを組み合わせたエージェンティックRAGが注目されています。従来のRAGが「検索→生成」の1回限りの処理であるのに対し、エージェンティックRAGは検索結果の品質を自律的に評価し、必要に応じて再検索や別のデータソースへの問い合わせを行います。
CRMデータとRAGを組み合わせれば、営業担当者が「この顧客への提案のポイントは?」と質問するだけで、過去の商談履歴、メールのやり取り、契約情報を横断的に検索し、根拠付きの提案アドバイスを生成するシステムが構築できます。データの一元管理とAI活用の基盤として、CRMの整備が重要な役割を果たします。
株式会社StartLinkは、事業推進に関わる「販売促進」「DXによる業務効率化(ERP/CRM/SFA/MAの導入)」などのご相談を受け付けております。 サービスのプランについてのご相談/お見積もり依頼や、ノウハウのお問い合わせについては、無料のお問い合わせページより、お気軽にご連絡くださいませ。
著者情報
